Decision trees are a machine learning technique for making predictions. They are built by repeatedly splitting training data into smaller and smaller samples. This post will explain how these splits are chosen.
Decision Tree algorithm comes under the family of supervised learning algorithms. Unlike other supervised learning algorithms, the decision tree algorithm is often used for solving regression and classification problems too.
Basic Decision Tree Terminologies
This process is illustrated below:
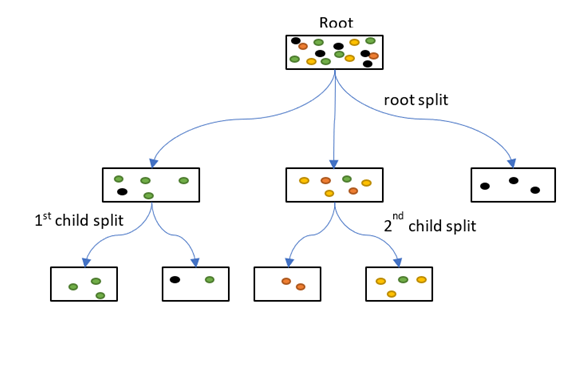
- Parent and Child Node: A node that gets divided into sub-nodes is known as Parent Node, and these sub-nodes are known as Child Nodes. Since a node can be divided into multiple sub-nodes, therefore a node can act as a parent node of numerous child nodes
- Root Node: The first node of a decision tree. It does not have any parent node. It represents the entire population or sample
- Leaf / Terminal Nodes: Nodes that do not have any child node are known as Terminal/Leaf Nodes
#machine learning

2.90 GEEK