Recommended Prerequisites: Understanding of Python (pandas & working with dataframes), Jupyter Notebook, SQL table operations and GitHub
Codes can be found here.
Having learned & used Python for about a year, I am no expert when it comes to data pipeline and cloud platform in general. This guide is my personal journey on learning new techniques and some things to keep in mind when developing a data solution.
- WHY CLOUD PLATFORM?
- BIG DATA / BIG LEARNING CURVE
- SETUP YOUR CLOUD PROJECT
- JUPYTER NOTEBOOK SETUP
- BIGQUERY SETUP
- SET UP WORKFLOW TEMPLATE TO BE RUN ON DATAPROC
- VISUALIZE ON GOOGLE DATA STUDIO
- LESSONS LEARNED
- NEXT STEPS
WHY CLOUD PLATFORM?
My unfamiliarity with a cloud platform like Google Cloud Platform (GCP) and Amazon Web Services (AWS) didn’t deter me from learning about them though I know it would be challenging at first. In a nutshell, cloud computing utilizes virtual machines (VM) to process jobs so you’re not confined by the computing power of your own local machine. Imagine running a python script that would take 2 hours to complete and you can’t use your PC to run other jobs at that time. Similar to multiprocessing, processing in the cloud would be split between VMs in a cluster to cut down processing time while increasing computing power. GCP also provides workflow templates that could be scheduled (eg. daily/weekly update) that would “spin up” a managed cluster to process task(s). In GCP, managed clusters are automatically ‘spinned down” after job completion or failures.
BIG DATA / BIG LEARNING CURVE
If you haven’t had any experience with big data, this tutorial would shine some light on that. GCP provides many tools that work in tandem to help you come up with your data solutions. The chart below describe the overall workflow:
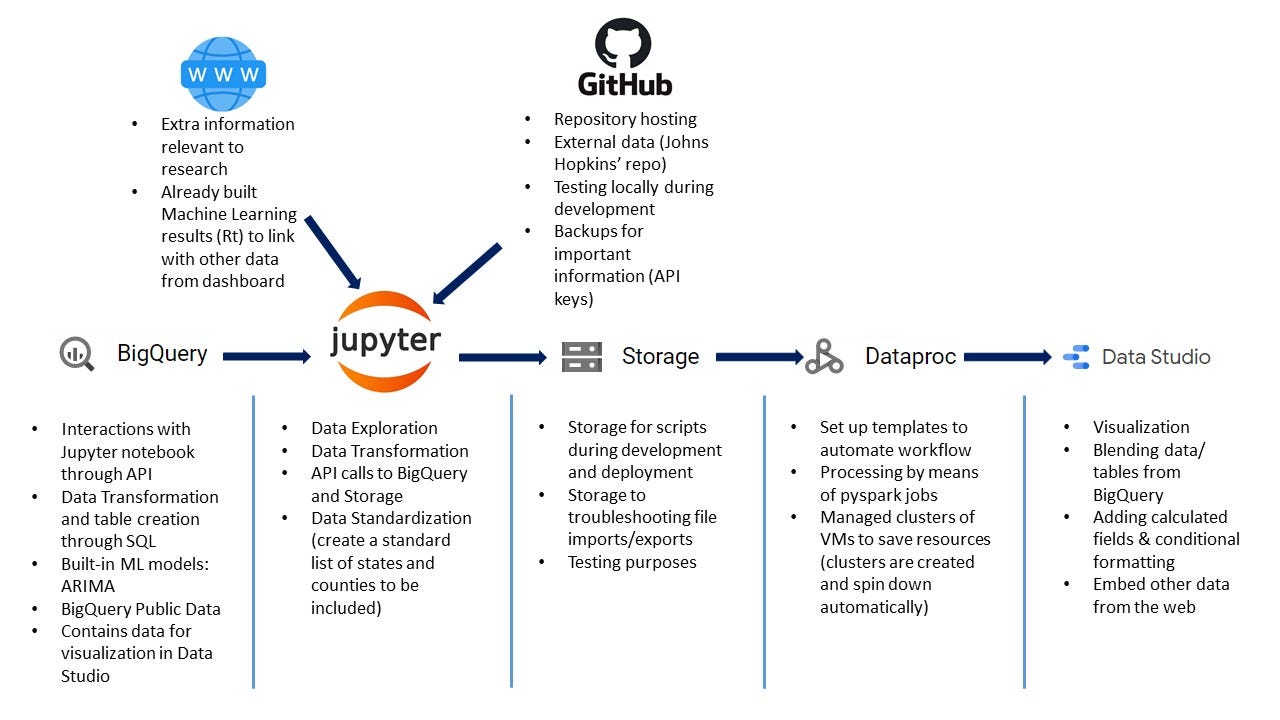
SETUP YOUR CLOUD PROJECT
Possibly the most challenging part of this project is to understand how everything works together and what’s the best way to link the services and resources in a way that is efficient. Let’s start with Google Cloud Authentication. If you’re a new customer, sign up for the Free Tier offer by Google and set up using that email. After that:
- Create a project (covid-jul25) and specify a region (us- west3-a) where your code will live. Interacting with the Cloud Console through CLI will require those information so keep them handy.
- Create a bucket inside the project that will be used for deployment & take note of this bucket
- Make sure to enable APIs for the following services: BigQuery, Storage and DataProc
- Service accounts should be set up for these services: BigQuery, Storage and Compute Engine (Compute Engine should already be set up by default)
- For LOCAL DEVELOPMENT ONLY, download the API json keys for BigQuery & Storage and store them in the same folder as your Jupyter notebook
#bigquery #cloud-services #etl #google-cloud-platform #python