Since the early days of machine learning, it has been attempted to learn good representations of data in an unsupervised manner. The hypothesis underlying this effort is that disentangled representations translate well to downstream supervised tasks. For example, if a human is told that a Tesla is a car and he has a good representation of what a car looks like, he can probably recognize a photo of a Tesla among photos of houses without ever seeing a Tesla.
Most early representation learning ideas revolve around linear models such as factor analysis, Principal Components Analysis (PCA) or sparse coding. Since these approaches are linear, they may not be able to find disentangled representations of complex data such as images or text. Especially in the context of images, simple transformations such as change of lighting may have very complex relationships to the pixel intensities. Therefore, there is a need for deep non-linear encoders and decoders, transforming data into its hidden (hopefully disentangled) representation and back.
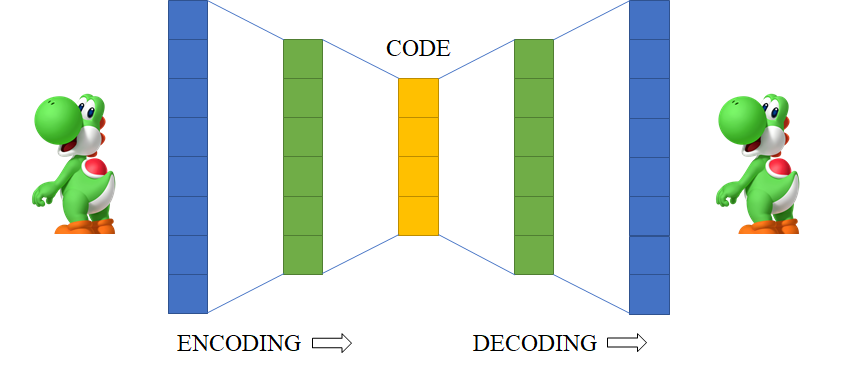
Autoencoders are neural network models designed to learn complex non-linear relationships between data points. Usually, autoencoders consist of multiple neural network layers and are trained to reconstruct the input at the output (hence the name _auto_encoder). In this post, I will try to give an overview of the various types of autoencoders developed over the years and their applications.
#deep-learning #machine-learning #autoencoder #ai