Preface
Google Analytics is widely used in various industries for tracking user activities in Web and mobile applications. For most of the users, the default reporting provided by GA is usually sufficient as long as the tracking of the application is in place (If not, go for the custom reporting! :p ).
Yet, once the business grows into a certain scale (20–50 employees or even bigger), there comes to a need to have the GA data available in a Data Warehouse for further in-depth analysis and even Machine Learning purposes.
Setup
The GA public data from BigQuery is used in the illustration:
SELECT *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
And the preview of the data would be looking like this:

The blanks come from the ARRAY, which we will discuss later
And for the ease of demonstration, we would also assume that the Data Warehouse is on BigQuery instead of the other tech (e.g. Redshift or Snowflake).
It would be very nice if you have a GCP (Google Cloud Platform) project up & running already, so you could follow this guideline to gain a better understanding.
Getting Started — Build a View in the Data Layer
The official documentation from Google can be found here: GA BigQuery Export schema.
The highlights are the visitStartTime column and the name of the table bigquery-public-data.google_analytics_sample.ga_sessions_20170801. In short, the naming pattern of the BigQuery tables is {GCP project name}.{Dataset name}.{Table name}.
As for BigQuery tables from the native export from GA, they are actually Shaded Tables. Shaded Tables basically mean that they are all different table objects, but following the exact same naming convention.
In this context, it would be the a series of tables like this:
bigquery-public-data.google_analytics_sample.ga_sessions_20170801bigquery-public-data.google_analytics_sample.ga_sessions_20170731bigquery-public-data.google_analytics_sample.ga_sessions_20170730
etc.
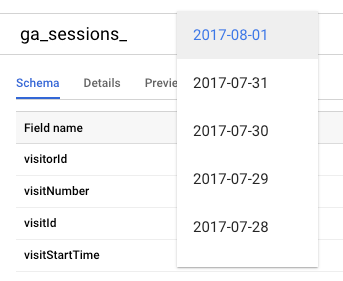
How does it look like for Shaded Tables in BigQuery Web Console
To query one of the tables, the code is pretty simple:
SELECT *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
Interesting question: What would you do if you wanna query more than 1 table with the exact same schema?
Answer: UNION ALL
SELECT *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
UNION ALL
SELECT *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170731`
The query above allows us to query data from 31 July to 1 August 2017. But obviously it doesn’t help a lot with actual business use cases. We would need MUCH more data than 2 days.
To tackle this, BigQuery provides the solution of Wildcard Tables. It means we could do something like this:
SELECT *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
Yup, the magic is the * after the ga_sessions_.
A general business user would think this is good enough already. But for a data professional (especially a data engineer), it isn’t.
To make it more maintainable and more readable by humans, we need 2 more columns here: created_at & created_date.
Why? Because the schema of the GA tables doesn’t come with the date with the DATE format. The date column in the tables is in STRING format. To align with the partitioning of the other tables in the Data Warehouse, the columns created_date and created_at are necessary.
Here is a sample query of running against the GA tables:
WITH ga_data AS (
SELECT PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) AS created_date
, TIMESTAMP_SECONDS(visitStartTime) AS created_at
, *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
)
SELECT *
FROM ga_data
WHERE 1=1
AND created_date = '2017-08-01'
The basic idea here is to leverage the non-materialistic nature of CTEs in BigQuery, and make it easier to build queries on top of it.
PARSE_DATE (Reference here) is a function taking a STRING value and return a DATE value. In this case, we are using the suffix of the Shaded Tables and cast it to DATE. By doing so, we could easily control which date’s data to fetch and to play with.
Assuming we have a dataset in the GCP project named dl as Data Layer, we could create the View with DDL for the GA data here:
CREATE OR REPLACE VIEW `dl.ga_sessions`
AS
SELECT PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) AS created_date
, TIMESTAMP_SECONDS(visitStartTime) AS created_at
, *
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
To consume data from the view, just simply run this query:
SELECT *
FROM `dl.ga_sessions`
WHERE 1=1
AND created_date = '2017-08-01'
Note that the project name is not a must in the query. If it is omitted, BigQuery would fallback to the GCP project that you are running the query in and look for the View there.
#google-analytics #arrays #data-science #bigquery #data #data analysis