In nearly every deep learning project, there is a decisive moment when immense volumes of training data or lack of processing power become the limiting factor of completing training in proper time. Therefore, applying appropriate scaling is inevitable. Although scaling up, i.e. upgrading to more powerful hardware, might deliver momentary remedies, seldom does it offer the right scalability because scaling up can rapidly hit its physical limits. Hence, we have no other option than to scale model training out, namely to use additional machines. Blissfully, scaling out in the era of cloud is not a hurdle anymore.
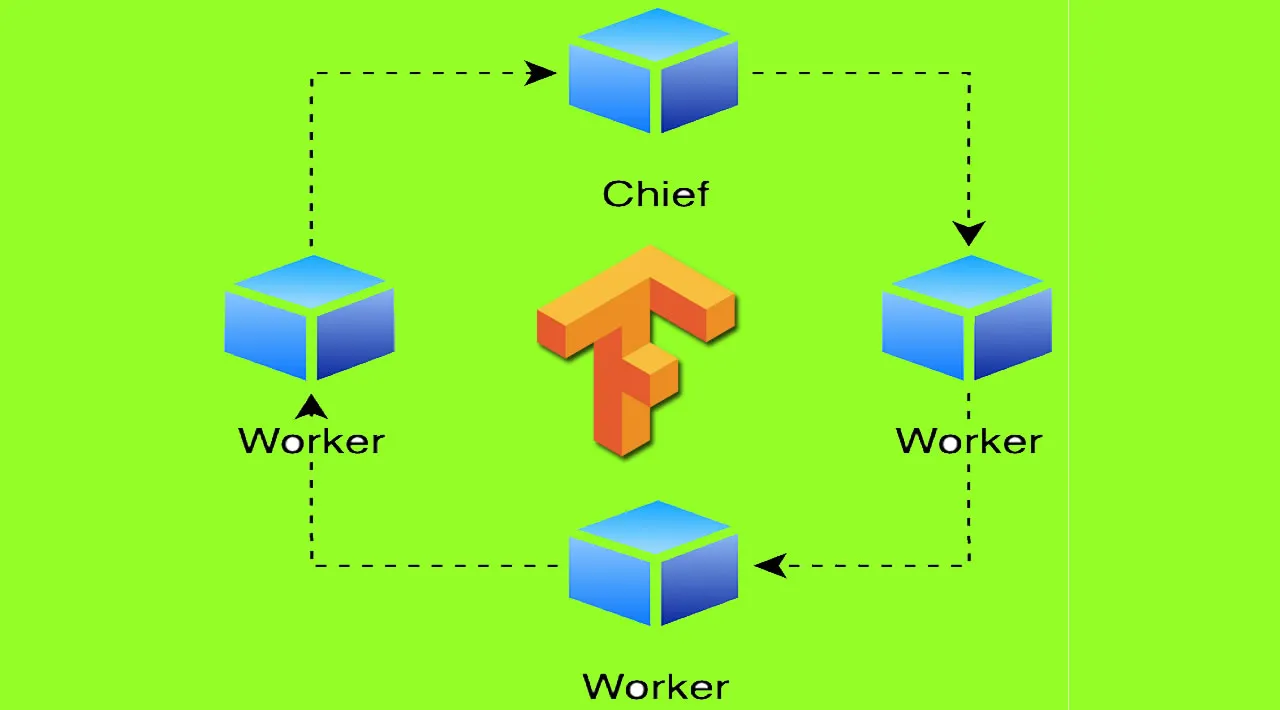
When it comes to scaling out neural network training, there are two main approaches. There is a strategy called model parallelism, in which the neural network itself gets split across multiple devices. This type of distribution gets mainly used in cases where the models consist of a multitude of parameters and would not otherwise fit on particular devices, or the sizes of input samples would impede even calculating activations. For those who are interested in model parallelism for Tensorflow, there is an official solution called Mesh.
#tensorflow #deep-learning #data-science #google-cloud-platform #distributed-training