ata is called as the _new oil _of 21st Century. It is very important to juggle with the data to extract and use the correct information to solve our problems. Working with data can be exciting and sometimes tedious for people. As it is rightly said, “Data Scientists spend 80% of their time cleaning the data”. Being a part of that pack, I go through the same process when encountering a new dataset. The same activity is not limited to until the Machine Learning(ML) system is implemented and deployed to production. When generating predictions in real time, the data might change due to unintuitive and unforseeable circumstances like error due to human interference, wrong data submitted, a new trend in data, problem while recording data, and many more. A simple ML system with multiple steps involved looks like shown in the diagram below:
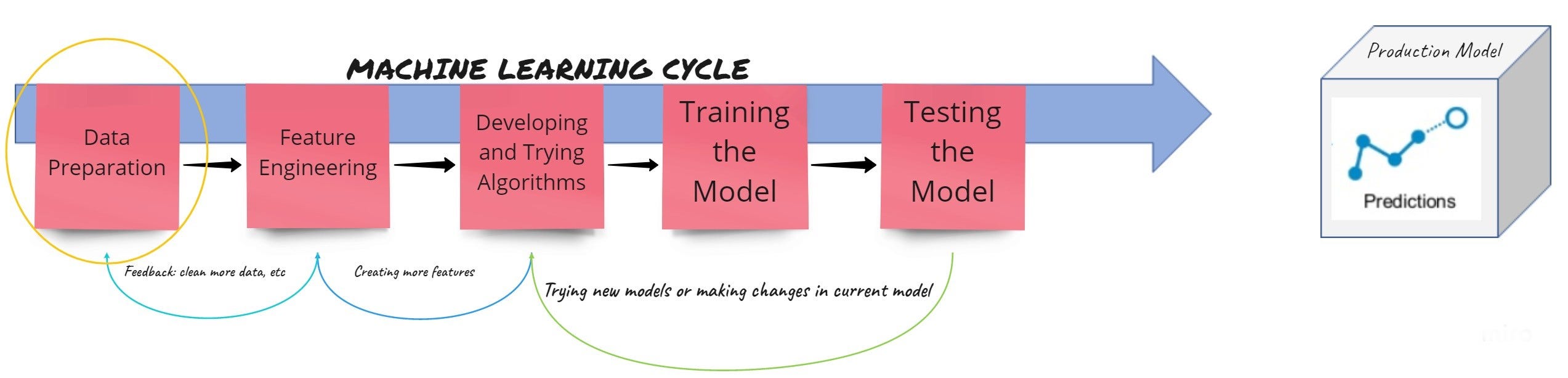
Image created by the author (Pratik Gandhi)
This needs to be slightly shifted by introducing or labeling another component explicitly, after data preparation and before feature engineering we name as Data Validation:
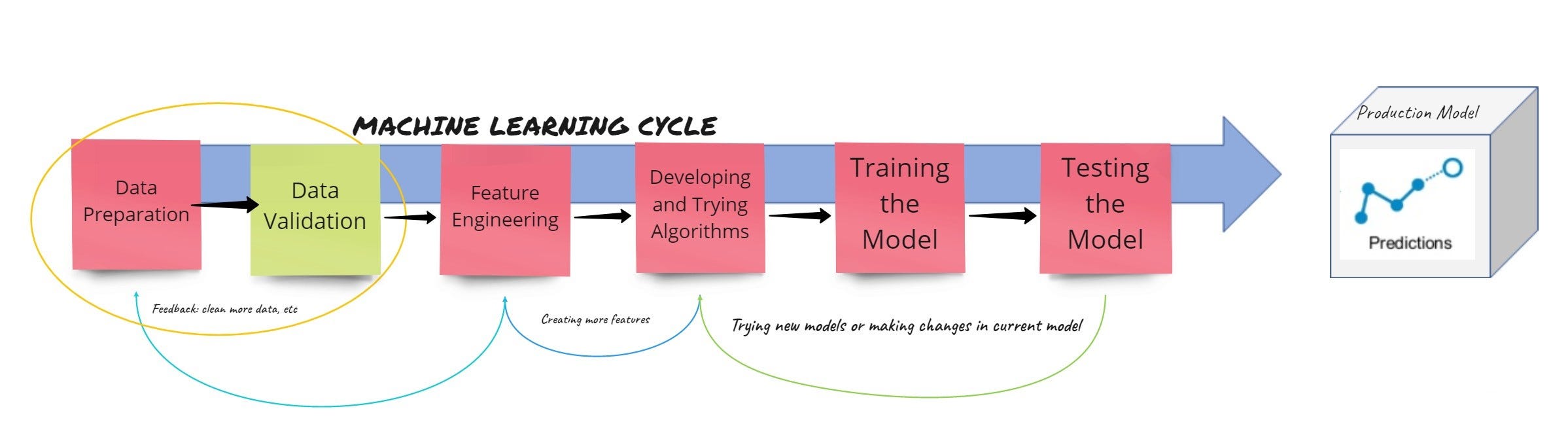
Image created by the author (Pratik Gandhi)
The article is focused on why data validation is important and how can one use different strategies to seemlessly integrate it in their pipeline. After some work, I learnt how to implement scripts that would do data validation to save some of the time. Above that, I **automated them **using some of the pre-built packages, stepping up my game!
Hear my Story!
Photo by Road Trip with Raj on Unsplash
Almost** 85%** of projects will not make it to production as per Gartner. Machine Learning (ML) Pipelines usually face several hiccups when pushed in production. One of the major issues I have quite often experienced is the compromise of data quality. Spending multiple hours of a day, several times a month maybe, and figuring out that the data that came through was unacceptable because of some reason can be quite relieving but frustrating at the same time. Many reasons can contribute that leads to data type getting changed like, text getting introduced instead of an integer, an integer was on outlier (probably 10 times higher) or an entire specific column was not received in the data feed, to mention a few. That is why adding this extra step is so important. Validating manually can take some extra effort and time. Making it automated(to an extent) could reduce the burden of the Data Science team. There are some major benefits I see by integrating an automated data validation in the pipeline:
#editors-pick #data-science #data #machine-learning #data-validation