We discuss quite a bit about going serverless for SMEs and startups, however it’s often those with an already huge infrastructure, such as enterprises, that can find the move and change daunting. We see many companies from the likes of Coca-Cola to Netflix managing it but what does it look like in action? In this article, we share some best practices and insights on the serverless designs that can scale massively and represent enterprise models. For a real life example, you can also check out how Shamrock Trading Corp migrated to serverless from a traditional cluster - psst, they’re also giving away their winning strategy for a smooth transition.
As AWS says, the most important foundation to keep in mind is that no matter the size, well-designed serverless applications are decoupled, stateless, and use minimal code. As the projects and applications grow, simplicity and low-code needs to be maintained.
Moving Away from Monoliths
While monolith designs can still suit some functionalities, with a business and application that is going serverless, moving away from this traditional style will save a huge amount of time. By grouping common functionalities together into smaller services and creating separate code repositories and microservices, the evolution of an application including new features will be more straightforward. This design also reduces security risks, deployment issues and bugs that can cross-contaminate.
So, what is the best way to group these?
Often, the best way to consider this is through the functions and resources that define a microservice. The design itself is also important; we don’t want to build a large repository that’ll end up as a monolith, however too many of them will mean duplicate code and difficulties in sharing resources. The aim here is to have one single piece of functionality that does that one thing very well.
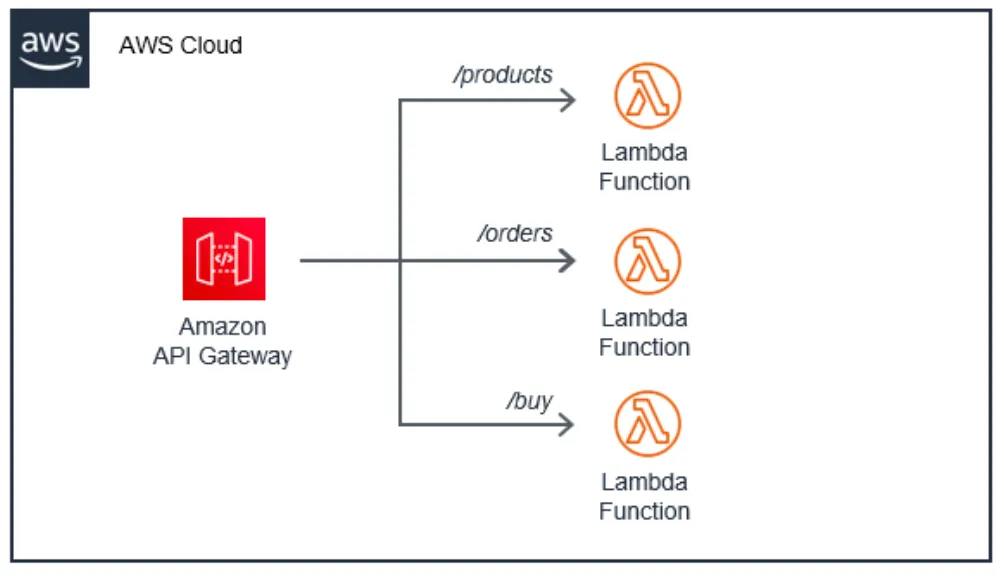
Consider Concurrency
It can be tempting, when using automatically scalable services such as AWS API Gateway and AWS Lambda, to not consider the backend relational database being used. We want a scale that will match demand - that’s one of the beauties of these serverless services at the end of the day! However, without the correct and, most importantly, necessary intermediary services to buffer requests, bottlenecks, throttling, outages and even loss of valuable data can occur due to exhaustion.
While API Gateway and Lambda are able to spin up thousands of concurrent requests quickly, it’s key to remember that not all AWS services are the same, such as AWS RDS. Instead, including services like AWS Kinesis or AWS SQS that poll for new records and can return findings to Lambda functions means greater control without any downtime or latency.
#aws #serverless #scaling #serverless adoption