TL;DR
In this article, we show you how to use TensorBoard in an Amazon SageMaker PyTorch training job in this blog. The steps are:
- Install TensorBoard at SageMaker training job runtime as here
- Configure tensorboard_output_config parameter when initializing PyTorch SageMaker estimator as here
- In PyTorch training script, log the data you want to monitor and visualize as here
- Startup tensorbard and point the log dir as the s3 location configured in step 2
Reason for This Blog
In one of my recent projects, I need to use TensorBoard to visualize metrics from a Amazon SageMaker PyTorch training jobs. After searching online and checking AWS official documents, SageMaker SDK examples and AWS blogs, I realize that there is no existing step-by-step tutorial for this topic. So, I write this article, and hopefully give you a ready-to-use solution.
How a SageMaker Training Job Exchanges Data between S3 and Training Instance
First, let us have a look the big picture when executing a PyTorch SageMaker training job. SageMaker facilities the process below:
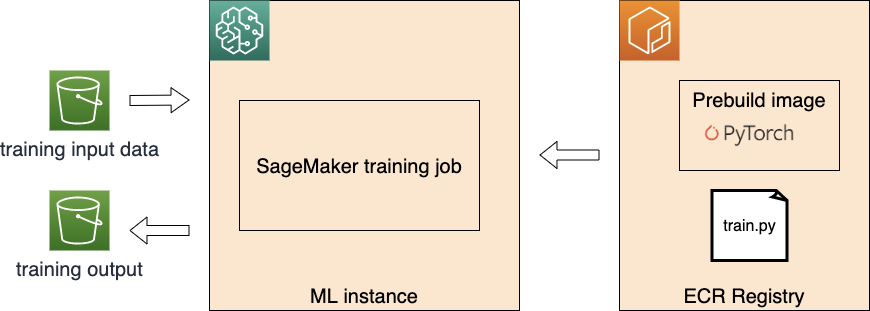
SageMaker Training Job
- Launch and prepare the requested ML instance(s)
- Download the input data from S3
- Pull the training image from ECR
- Execute the traing file (train.py in the figure above) as the entry point of training
- Push the training model artifact back to S3
Let us zoom in how data exchange between ML instance and S3 by the example below. Here we use SageMaker Python SDK.
#machine-learning #sagemaker #tensorboard #pytorch #deep learning