Jupiter notebook上でパイソンを動かしています。
ボストンのデータを読み込み、ZN,INDUS,CRIMを用いてロジスティック回帰を行いたいです。
#課題4_主成分分析
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_boston
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Lasso
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import sklearn
from sklearn.decomposition import PCA #主成分分析器
from sklearn import preprocessing
%matplotlib inline
boston = load_boston()
boston = pd.DataFrame(boston.data, columns=boston.feature_names)
#行列の標準化をすると,CHAS要素を削除するときに
#なぜかCRIMも消えてしまうため実行しない
#boston = boston.iloc[:, 1:].apply(lambda x: (x-x.mean())/x.std(), axis=0)
#主成分分析の実行
pca = PCA()
pca.fit(boston)
## データを主成分空間に写像
feature = pca.transform(boston)
pd.DataFrame(pca.explained_variance_ratio_, index=["PC{}".format(x + 1) for x in range(len(boston.columns))])
## PCA の固有値
koyuchi = pd.DataFrame(pca.explained_variance_, index=["PC{}".format(x + 1) for x in range(len(boston.columns))])
#列要素を削除
boston.drop("LSTAT",axis=1,inplace=True)
boston.drop("B",axis=1,inplace=True)
boston.drop("PTRATIO",axis=1,inplace=True)
boston.drop("TAX",axis=1,inplace=True)
boston.drop("RAD",axis=1,inplace=True)
boston.drop("DIS",axis=1,inplace=True)
boston.drop("AGE",axis=1,inplace=True)
boston.drop("RM",axis=1,inplace=True)
boston.drop("NOX",axis=1,inplace=True)
boston.drop("CHAS",axis=1,inplace=True)
X = preprocessing.scale(boston[["INDUS","CRIM",]])
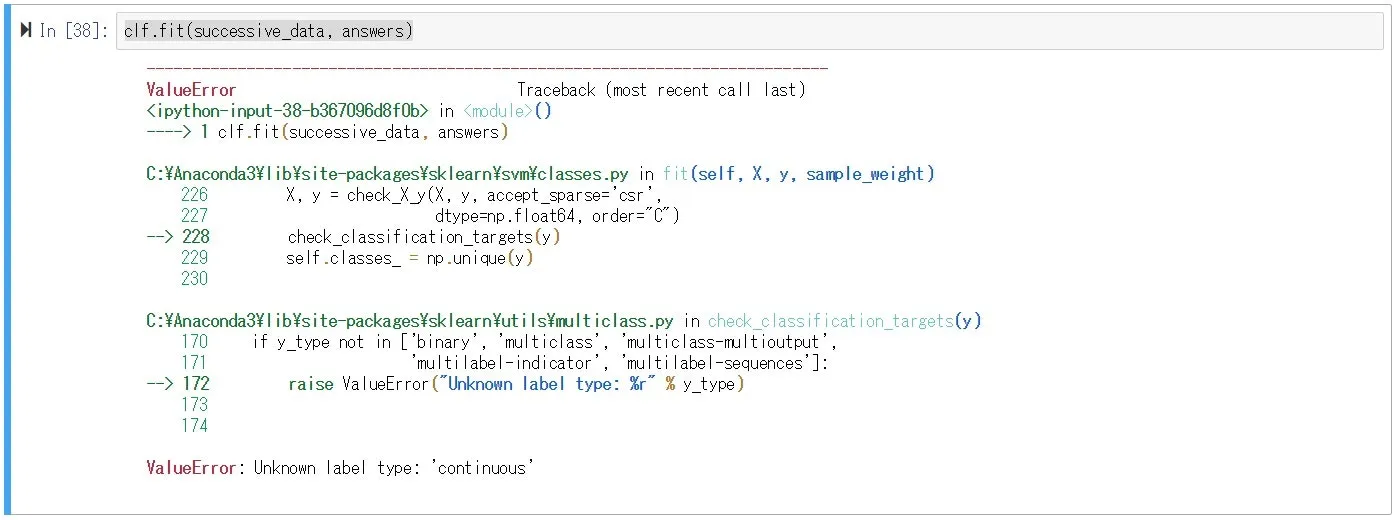
Y =boston["ZN"]#正解データ:整数のものを選んだ
#トレーニングデータとテストデータを7:3に分ける
X_tr, X_te, Y_tr, Y_te = train_test_split(X, Y, test_size=0.3, random_state=7 )
from sklearn.linear_model import LogisticRegression
## ロジスティック回帰モデルのインスタンス
lr = LogisticRegression()
## トレーニングデータから,ロジスティック回帰モデルの重みを学習
lr.fit(X_tr, Y_tr)
## テストデータにおける検証を行う.
Y_pred = lr.predict(X_te)
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
#混同行列
print('confusion matrix = \n', confusion_matrix(y_true=Y_te, y_pred=Y_pred))
#正確度
print('accuracy = ', accuracy_score(y_true=Y_te, y_pred=Y_pred))
#汎化誤差
print('汎化誤差 = ', 1-accuracy_score(y_true=Y_te, y_pred=Y_pred))
#適合率
#print('precision = ', precision_score(y_true=Y_te, y_pred=Y_pred))
#F値
print('f1 score = ', f1_score(y_true=Y_te, y_pred=Y_pred , average='micro'))
#python
7.15 GEEK