For Natural Language Processing, clean data is important. Even more so when that data is coming from the web. In this article we will go through a real example of web scraping and data pre-processing for a Stoic philosophy text generator.The data we will be using is Epistulae Morales Ad Lucilium (Moral Letters to Lucilius) written by exiled Roman senator Seneca during the late Stoa.
Epistulae
The letters are sourced from WikiSource here. This page consists of a list of all 124 letters. Where each letter is contained in it’s own page.

First, we must extract the HTML from this contents page. For this we use Python’s requests and BeautifulSoup libraries.
import requests
from bs4 import BeautifulSoup
# import page containing links to all of Seneca's letters
# get web address
src = "https://en.wikisource.org/wiki/Moral_letters_to_Lucilius"
html = requests.get(src).text # pull html as text
soup = BeautifulSoup(html, "html.parser") # parse into BeautifulSoup object
view raw
hello_lucilius_import.py hosted with ❤ by GitHub
This gives us a BeautifulSoup object, which contains the raw html we have given via html. Let’s take a look what this looks like.
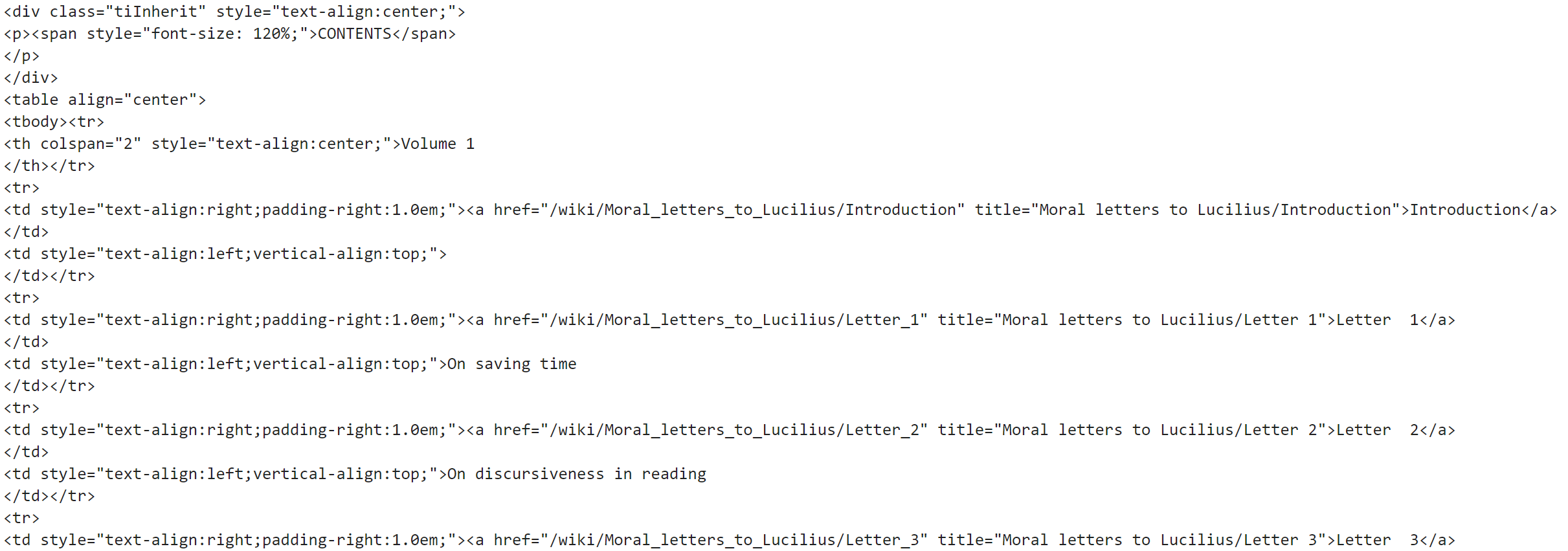
In this, we must extract the local paths to each letter. The BeautifulSoup object allows us to extract all <a> elements with soup.find_all('a'). However, this returns **all **<a> elements, so we then need to filter for just those which link to the letters.We do this using regular expressions, which is incredibly simple, we build our regex to search for anything that begins with Letter followed by one or more spaces \s+ and finally ending with one to three digits \d{1,3}. This gives us re.compile(r"^Letter\s+\d{1,3}$").By applying this regex to the list of <a> elements provided by BeautifulSoup, we will get the following.
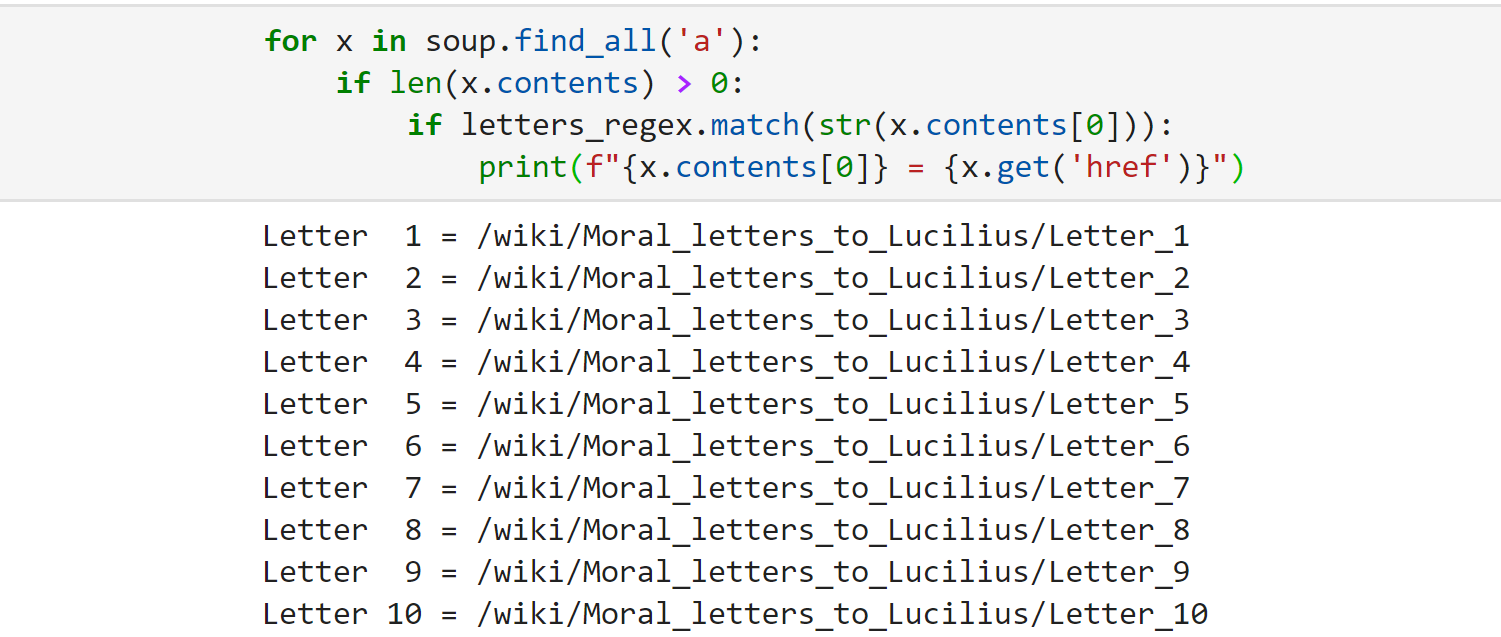
Unum Epistula Legimus
Now we need to define a function to parse the HTML from each page. This is actually very straight-forward, as the letter text is all contained in the only <p> elements on the page.
#artificial-intelligence #web-scraping #programming #machine-learning #data-science #data analysis