SCAN is a powerful tool for querying data, but its blocking nature can destroy performance when used heavily. KeyDB has changed the nature of this command in its Pro edition, allowing orders of magnitude performance improvement!
This article looks at the limitations of using the SCAN command and the effects it has on performance. It demonstrates the major performance degredation that occurs with Redis, and it also looks at how KeyDB Pro solved this by implementing a MVCC architecture allowing SCAN to be non-blocking, avoiding any negative impacts to performance.
KEYS vs SCAN
The SCAN function was created to break up the blocking KEYS command which could present major issues when used in production. Many Redis users know too well the consequences of this slowdown on their production workloads.
The KEYS command and SCAN command can search for all keys matching a certain pattern. The difference between the two is that SCAN iterates through the keyspace in batches with a cursor to prevent completely blocking the database for the length of the query.
Basic usage is as following:
Shell
1
keydb-cli:6379> KEYS [pattern]
2
keydb-cli:6379> SCAN cursor [MATCH pattern] [COUNT count]
The example below searches all keys containing the pattern “22” in it. The cursor starts at position 0 and searches through 100 keys at a time. The returned result will first return the next cursor number, and all the values in the batch that contained “22” in the key name.
Shell
1
keydb-ci: 6379> SCAN 0 MATCH *22* COUNT 100
2
1) 2656
3
2) 1) 220
4
2) 3022
5
3) 4224
6
4) 22
For more information on using SCAN please see documentation here https://docs.keydb.dev/docs/commands/#scan
SCAN COUNT
The COUNT is the number of keys to search through at a time per cursor iteration. As such the smaller the count, the more incremental iterations required for a given data set. Below is a chart showing the execution time to go through a dataset of 5 million keys using various COUNT settings.
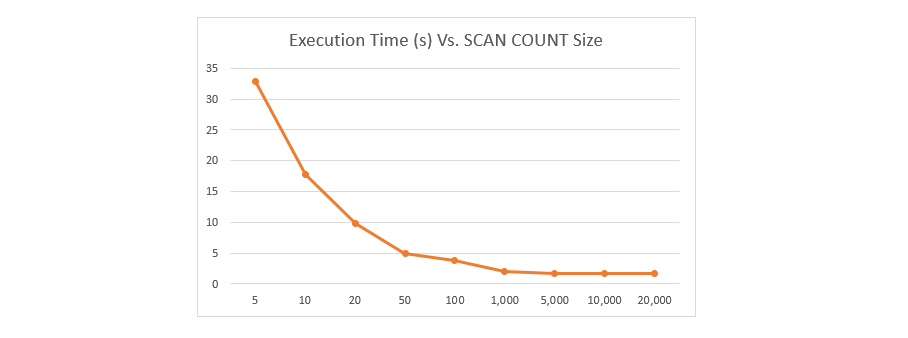 As can be noted, for very small count sizes, the time it takes to iterate through all the keys goes up significantly. Grouping into larger amounts results in lower latency for the SCAN to complete. Batch sizes of 1000 or greater return results much faster.
As can be noted, for very small count sizes, the time it takes to iterate through all the keys goes up significantly. Grouping into larger amounts results in lower latency for the SCAN to complete. Batch sizes of 1000 or greater return results much faster.
With Redis it is important to select a size small enough to minimize the blocking behavior of the command during production.
#database #tutorial #devops
