Phân đoạn hình ảnh với Trình phân loại Bayes thông thường và OpenCV
Tìm hiểu cách sử dụng thuật toán Normal Bayes Classifier để phân đoạn hình ảnh bằng OpenCV, thư viện thị giác máy tính lớn nhất thế giới.
Nhắc nhở về Định lý Bayes khi áp dụng vào Machine Learning
Hướng dẫn này của Jason Brownlee đưa ra lời giải thích sâu sắc về Định lý Bayes cho học máy, vì vậy trước tiên hãy bắt đầu bằng việc tìm hiểu một số điểm quan trọng nhất từ hướng dẫn của anh ấy:
Định lý Bayes rất hữu ích trong học máy vì nó cung cấp một mô hình thống kê để hình thành mối quan hệ giữa dữ liệu và giả thuyết.
- Được biểu diễn dưới dạng �(ℎ|�)=�(�|ℎ)∗�(ℎ)/�(�), Định lý Bayes phát biểu rằng xác suất của một giả thuyết cho trước là đúng (ký hiệu là �(ℎ |�) và được gọi là xác suất hậu nghiệm của giả thuyết) có thể được tính theo:
-
- Xác suất quan sát dữ liệu đưa ra giả thuyết (ký hiệu là �(�|ℎ) và được gọi là khả năng).khả năng xảy ra).
- Xác suất của giả thuyết là đúng, độc lập với dữ liệu (ký hiệu là �(ℎ) và được gọi là xác suất trước của giả thuyết).
- Xác suất quan sát dữ liệu độc lập với giả thuyết (ký hiệu là �(�) và được gọi là bằng chứng).
- Định lý Bayes giả định rằng mọi biến (hoặc đặc điểm) tạo nên dữ liệu đầu vào, �, phụ thuộc vào tất cả các biến (hoặc đặc điểm) khác.
- Trong bối cảnh phân loại dữ liệu, Định lý Bayes có thể được áp dụng cho bài toán tính xác suất có điều kiện của nhãn lớp cho một mẫu dữ liệu: �(����||����)=�(���� |�����)∗�(�����)/�(����), trong đó nhãn lớp bây giờ thay thế giả thuyết. Bằng chứng �(����), là một hằng số và có thể bị loại bỏ.
- Trong việc xây dựng bài toán như đã nêu ở gạch đầu dòng ở trên, việc ước tính khả năng xảy ra, �(����|�����), có thể khó khăn vì nó đòi hỏi số lượng mẫu dữ liệu đủ lớn để chứa tất cả các kết hợp có thể có của các biến (hoặc tính năng) cho mỗi lớp. Điều này hiếm khi xảy ra, đặc biệt với dữ liệu nhiều chiều có nhiều biến số.
- Công thức trên có thể được đơn giản hóa thành cái được gọi là Naive Bayes, trong đó mỗi biến đầu vào được xử lý riêng biệt: �(��� ��|�1,�2,…,��)=�(�1|�����)∗�(�2|�����)∗⋯∗�(��|���� �)∗�(�����)
- Ước tính Naive Bayes thay đổi công thức từ mô hình xác suất có điều kiện phụ thuộc thành mô hình độc lập. ngây thơ mô hình xác suất có điều kiện, trong đó các biến (hoặc đặc điểm) đầu vào hiện được giả định là độc lập. Giả định này hiếm khi đúng với dữ liệu trong thế giới thực, do đó có tên
Khám phá phân loại Bayes trong OpenCV
Giả sử dữ liệu đầu vào mà chúng ta đang làm việc là liên tục. Trong trường hợp đó, nó có thể được mô hình hóa bằng cách sử dụng phân phối xác suất liên tục, chẳng hạn như phân phối Gaussian (hoặc bình thường), trong đó dữ liệu thuộc mỗi lớp được mô hình hóa bằng giá trị trung bình và độ lệch chuẩn của nó.
Trình phân loại Bayes được triển khai trong OpenCV là trình phân loại Bayes bình thường (còn được gọi là Gaussian Naive Bayes), giả định rằng các tính năng đầu vào của mỗi lớp được phân phối chuẩn.
Mô hình phân loại đơn giản này giả định rằng các vectơ đặc trưng từ mỗi lớp được phân phối bình thường (tuy nhiên, không nhất thiết phải được phân phối độc lập).
– OpenCV, Tổng quan về học máy, 2023.
Để khám phá cách sử dụng trình phân loại Bayes thông thường trong OpenCV, hãy bắt đầu bằng cách thử nghiệm nó trên một tập dữ liệu hai chiều đơn giản, như chúng tôi đã làm trong các hướng dẫn trước.
Với mục đích này, hãy tạo một tập dữ liệu bao gồm 100 điểm dữ liệu (được chỉ định bởi n_samples), được chia đều thành 2 cụm Gaussian (được xác định bởi centers) có độ lệch chuẩn được đặt thành 1,5 (được chỉ định bởi cluster_std). Chúng ta cũng hãy xác định giá trị cho random_state để có thể sao chép kết quả:
# Generating a dataset of 2D data points and their ground truth labels
x, y_true = make_blobs(n_samples=100, centers=2, cluster_std=1.5, random_state=15)
# Plotting the dataset
scatter(x[:, 0], x[:, 1], c=y_true)
show()
Đoạn mã trên sẽ tạo ra biểu đồ các điểm dữ liệu sau:
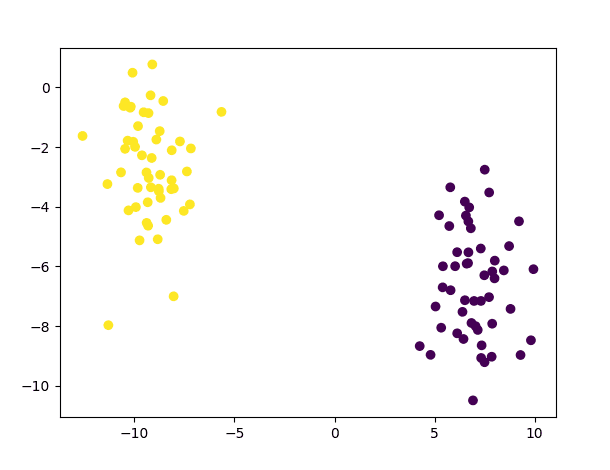
Sơ đồ phân tán của tập dữ liệu gồm 2 cụm Gaussian
Sau đó, chúng tôi sẽ chia tập dữ liệu này, phân bổ 80% dữ liệu cho tập huấn luyện và 20% còn lại cho tập kiểm tra:
# Split the data into training and testing sets
x_train, x_test, y_train, y_test = ms.train_test_split(x, y_true, test_size=0.2, random_state=10)Sau đó, chúng tôi sẽ tạo trình phân loại Bayes bình thường và tiến hành đào tạo và thử nghiệm nó trên các giá trị tập dữ liệu sau khi chuyển kiểu sang float 32 bit:
Python
# Create a new Normal Bayes Classifier
norm_bayes = ml.NormalBayesClassifier_create()
# Train the classifier on the training data
norm_bayes.train(x_train.astype(float32), ml.ROW_SAMPLE, y_train)
# Generate a prediction from the trained classifier
ret, y_pred, y_probs = norm_bayes.predictProb(x_test.astype(float32))Bằng cách sử dụng phương thức predictProb, chúng ta sẽ thu được lớp được dự đoán cho mỗi vectơ đầu vào (với mỗi vectơ được lưu trữ trên mỗi hàng của mảng được đưa vào trình phân loại Bayes thông thường) và xác suất đầu ra.
Trong đoạn mã trên, các lớp được dự đoán được lưu trữ trong y_pred, trong khi y_probs là một mảng có nhiều cột như các lớp (trong trường hợp này là hai cột ) chứa giá trị xác suất của từng vectơ đầu vào thuộc từng lớp đang được xem xét. Sẽ hợp lý nếu các giá trị xác suất đầu ra mà bộ phân loại trả về cho mỗi vectơ đầu vào có tổng bằng một. Tuy nhiên, điều này có thể không nhất thiết đúng vì các giá trị xác suất mà bộ phân loại trả về không được chuẩn hóa bằng bằng chứng, �(����), mà chúng ta đã loại bỏ khỏi mẫu số, như đã giải thích trong phần trước.
Thay vào đó, cái được báo cáo là khả năng xảy ra, về cơ bản là tử số của phương trình xác suất có điều kiện, p(C) p(M | C). Mẫu số, p(M), không cần phải tính toán.
– Học máy cho OpenCV, 2017.
Tuy nhiên, cho dù các giá trị có được chuẩn hóa hay không, dự đoán lớp cho mỗi vectơ đầu vào có thể được tìm thấy bằng cách xác định lớp có giá trị xác suất cao nhất.
Danh sách mã cho đến nay là như sau:
from sklearn.datasets import make_blobs
from sklearn import model_selection as ms
from numpy import float32
from matplotlib.pyplot import scatter, show
from cv2 import ml
# Generate a dataset of 2D data points and their ground truth labels
x, y_true = make_blobs(n_samples=100, centers=2, cluster_std=1.5, random_state=15)
# Plot the dataset
scatter(x[:, 0], x[:, 1], c=y_true)
show()
# Split the data into training and testing sets
x_train, x_test, y_train, y_test = ms.train_test_split(x, y_true, test_size=0.2, random_state=10)
# Create a new Normal Bayes Classifier
norm_bayes = ml.NormalBayesClassifier_create()
# Train the classifier on the training data
norm_bayes.train(x_train.astype(float32), ml.ROW_SAMPLE, y_train)
# Generate a prediction from the trained classifier
ret, y_pred, y_probs = norm_bayes.predictProb(x_test.astype(float32))
# Plot the class predictions
scatter(x_test[:, 0], x_test[:, 1], c=y_pred)
show()Chúng ta có thể thấy rằng các dự đoán về lớp do trình phân loại Bayes bình thường được đào tạo trên tập dữ liệu đơn giản này tạo ra là chính xác:

Biểu đồ phân tán dự đoán được tạo cho các mẫu thử nghiệm
Phân đoạn hình ảnh bằng cách sử dụng bộ phân loại Bayes thông thường
Trong số nhiều ứng dụng của họ, bộ phân loại Bayes thường được sử dụng để phân đoạn da, giúp phân tách các pixel da khỏi các pixel không phải da trong một hình ảnh.
Chúng tôi có thể điều chỉnh mã ở trên để phân đoạn pixel da trong hình ảnh. Với mục đích này, chúng tôi sẽ sử dụng tập dữ liệu Phân đoạn da, bao gồm 50.859 mẫu da và 194.198 mẫu không phải da, để huấn luyện bộ phân loại Bayes thông thường. Tập dữ liệu trình bày các giá trị pixel theo thứ tự BGR và nhãn lớp tương ứng của chúng.
Sau khi tải tập dữ liệu, chúng tôi sẽ chuyển đổi các giá trị pixel BGR thành HSV (biểu thị Hue, Saturation và Value), sau đó sử dụng các giá trị màu sắc để huấn luyện bộ phân loại Bayes bình thường. Hue thường được ưu tiên hơn RGB trong các tác vụ phân đoạn hình ảnh vì nó thể hiện màu sắc trung thực mà không cần sửa đổi và ít bị ảnh hưởng bởi sự thay đổi ánh sáng hơn RGB. Trong mô hình màu HSV, các giá trị màu sắc được sắp xếp theo hướng tỏa tâm và trải dài trong khoảng từ 0 đến 360 độ:
from cv2 import ml,
from numpy import loadtxt, float32
from matplotlib.colors import rgb_to_hsv
# Load data from text file
data = loadtxt("Data/Skin_NonSkin.txt", dtype=int)
# Select the BGR values from the loaded data
BGR = data[:, :3]
# Convert to RGB by swapping the array columns
RGB = BGR.copy()
RGB[:, [2, 0]] = RGB[:, [0, 2]]
# Convert RGB values to HSV
HSV = rgb_to_hsv(RGB.reshape(RGB.shape[0], -1, 3) / 255)
HSV = HSV.reshape(RGB.shape[0], 3)
# Select only the hue values
hue = HSV[:, 0] * 360
# Select the labels from the loaded data
labels = data[:, -1]
# Create a new Normal Bayes Classifier
norm_bayes = ml.NormalBayesClassifier_create()
# Train the classifier on the hue values
norm_bayes.train(hue.astype(float32), ml.ROW_SAMPLE, labels)Lưu ý 1: Thư viện OpenCV cung cấp phương thức cvtColor để chuyển đổi giữa các không gian màu, như được thấy trong hướng dẫn này, nhưng phương thức cvtColor yêu cầu hình ảnh nguồn ở hình dạng ban đầu làm đầu vào. Mặt khác, phương thức rgb_to_hsv trong Matplotlib chấp nhận một mảng NumPy ở dạng (…, 3) làm đầu vào, trong đó các giá trị mảng dự kiến sẽ được chuẩn hóa trong phạm vi từ 0 đến 1. Ở đây chúng tôi đang sử dụng cái sau vì dữ liệu huấn luyện của chúng tôi bao gồm các pixel riêng lẻ, không được cấu trúc ở dạng hình ảnh ba kênh thông thường.
Lưu ý 2: Trình phân loại Bayes thông thường giả định rằng dữ liệu được mô hình hóa tuân theo phân bố Gaussian. Mặc dù đây không phải là một yêu cầu nghiêm ngặt nhưng hiệu suất của bộ phân loại có thể giảm nếu dữ liệu được phân phối theo cách khác. Chúng tôi có thể kiểm tra việc phân phối dữ liệu mà chúng tôi đang làm việc bằng cách vẽ biểu đồ của nó. Nếu lấy giá trị màu sắc của các pixel da làm ví dụ, chúng tôi sẽ thấy rằng đường cong Gaussian có thể mô tả sự phân bố của chúng:
from numpy import histogram
from matplotlib.pyplot import bar, title, xlabel, ylabel, show
# Choose the skin-labelled hue values
skin = x[labels == 1]
# Compute their histogram
hist, bin_edges = histogram(skin, range=[0, 360], bins=360)
# Display the computed histogram
bar(bin_edges[:-1], hist, width=4)
xlabel('Hue')
ylabel('Frequency')
title('Histogram of the hue values of skin pixels')
show()
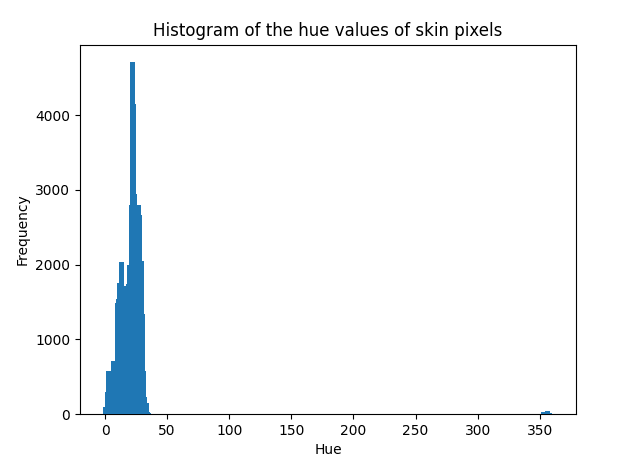
Kiểm tra phân phối dữ liệu
Khi trình phân loại Bayes bình thường đã được đào tạo, chúng tôi có thể kiểm tra nó trên một hình ảnh (hãy xem xét hình ảnh ví dụ này để kiểm tra):
from cv2 import imread
from matplotlib.pyplot import show, imshow
# Load a test image
face_img = imread("Images/face.jpg")
# Reshape the image into a three-column array
face_BGR = face_img.reshape(-1, 3)
# Convert to RGB by swapping the array columns
face_RGB = face_BGR.copy()
face_RGB[:, [2, 0]] = face_RGB[:, [0, 2]]
# Convert from RGB to HSV
face_HSV = rgb_to_hsv(face_RGB.reshape(face_RGB.shape[0], -1, 3) / 255)
face_HSV = face_HSV.reshape(face_RGB.shape[0], 3)
# Select only the hue values
face_hue = face_HSV[:, 0] * 360
# Display the hue image
imshow(face_hue.reshape(face_img.shape[0], face_img.shape[1]))
show()
# Generate a prediction from the trained classifier
ret, labels_pred, output_probs = norm_bayes.predictProb(face_hue.astype(float32))
# Reshape array into the input image size and choose the skin-labelled pixels
skin_mask = labels_pred.reshape(face_img.shape[0], face_img.shape[1], 1) == 1
# Display the segmented image
imshow(skin_mask, cmap='gray')
show()Mặt nạ phân đoạn thu được sẽ hiển thị các pixel được gắn nhãn thuộc về da (với nhãn lớp bằng 1).
Bằng cách phân tích kết quả một cách định tính, chúng ta có thể thấy rằng hầu hết các pixel trên da đã được gắn nhãn chính xác như vậy. Chúng ta cũng có thể thấy rằng một số sợi tóc (do đó, các pixel không phải da) đã được gắn nhãn không chính xác là thuộc về da. Nếu chúng ta phải xem xét các giá trị màu sắc của chúng, chúng ta có thể nhận thấy rằng chúng rất giống với các giá trị thuộc về vùng da, do đó gây nhầm lẫn. Hơn nữa, chúng ta cũng có thể nhận thấy tính hiệu quả của việc sử dụng các giá trị màu sắc, giá trị này vẫn tương đối ổn định ở các vùng trên khuôn mặt trông có vẻ được chiếu sáng hoặc trong bóng tối trong ảnh RGB gốc:
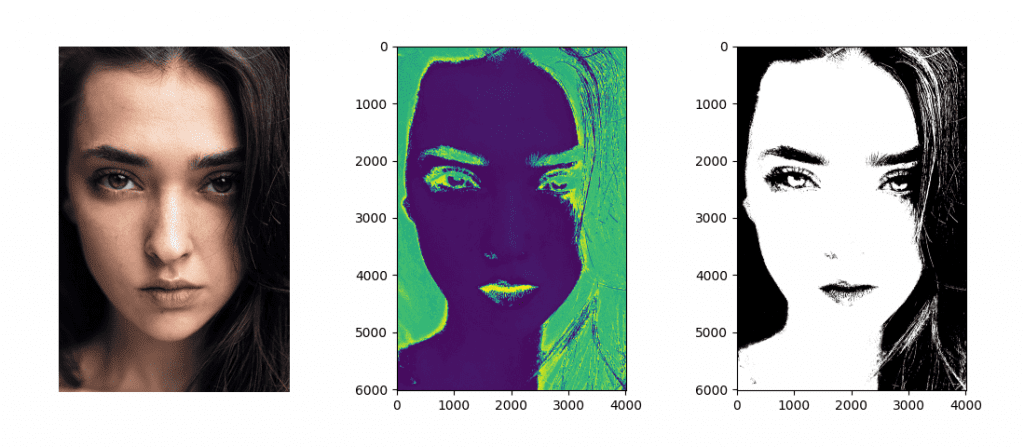
Ảnh gốc (Trái); Giá trị Huế (Trung bình); Pixel da được phân đoạn (Phải)
Bạn có thể nghĩ ra nhiều thử nghiệm hơn để thử với bộ phân loại Bayes bình thường không?
