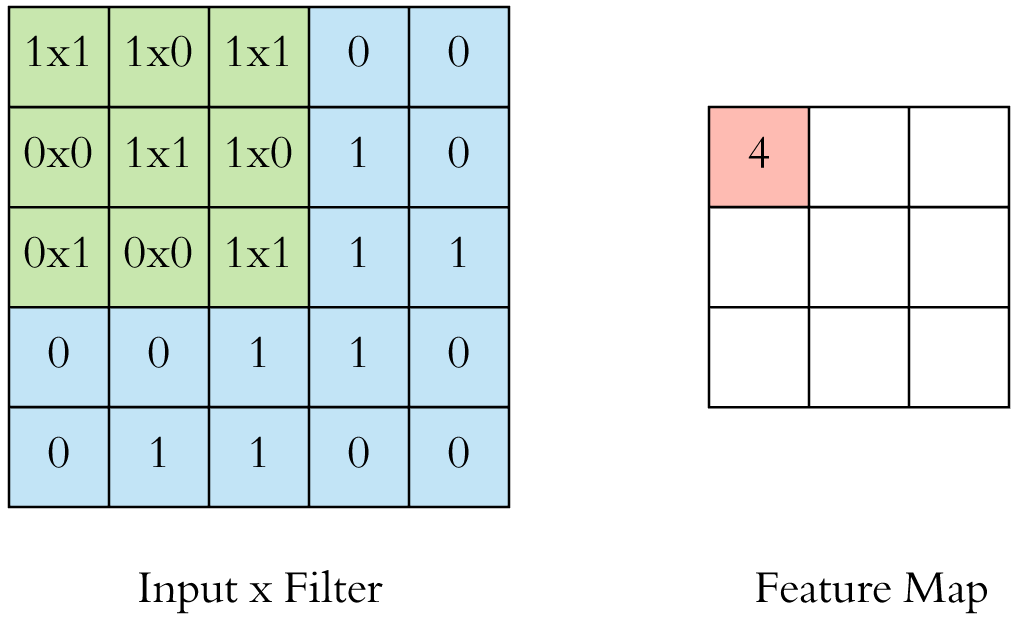
Convolution is basically a dot product of kernel (or filter) and patch of an image (local receptive field) of the same size. Convolution is quite similar to correlation and exhibits a property of translation equivariant that means if we move or translate the input and apply the convolution to it, it will act in the same manner as we first apply convolution and then translated an image.
During this learning process of CNN, you find different kernel sizes at different places in the code, then this question arises in one’s mind that whether there is a specific way to choose such dimensions or sizes. So, the answer is no. In the current Deep Learning world, we are using the most popular choice that is used by every Deep Learning practitioner out there, and that is 3x3 kernel size. Now, another question strikes your mind, why only 3x3, and not 1x1, 2x2, 4x4, etc. Just keep reading and you will getthe most crisp reason behind this in next few minutes!!
#convolutional-network #data-science #neural-networks #cnn #deeplearing