Introduction
Classification is a type of supervised learning in Machine Learning that deals with categorizing data into classes. Supervised learning implies models that take input with their matched output to train a model which can later make useful predictions on a new set of data with no output. Some examples of classification problems include: _spam detection in mails, subscription analysis, hand written digit recognition, survival predictions _et.c. They all involve the use of classifiers that utilize the train data to understand how the input variables relate to the output (target) variable.
Photo by Mitchell Schwartz on Unsplash
**Class imbalance **refers to a problem in classification where the distribution of the classes are skewed. This can range from a slight to an extreme imbalance.
This is a problem because most classification algorithms will have a low prediction accuracy towards the minority class because they run with the assumption that there’s balance between the classes.
An example of class imbalance is in credit card fraud detection. The classes, in this case, are fraud and not fraud. Most of the transactions are not fraud, thus the fraud classes are the minority class. Having a low accuracy in the minority class predictions is problematic because it is the most important class.
This blog covers the steps involved in tackling a classification problem in imbalanced dataset. The Github repository containing all the code is available here.
Dataset
Data used is from the UCI Machine Learning Repository. The data is related with marketing campaigns of a Portuguese banking institution. The classification goal is to predict if the client will subscribe to a term deposit (variable y).
An effective model can help increase campaign efficiency as more efforts can be directed towards customers with high subscription chances.
Sample of the data:

Visualizing the target variable(y) in order to observe the class imbalance:
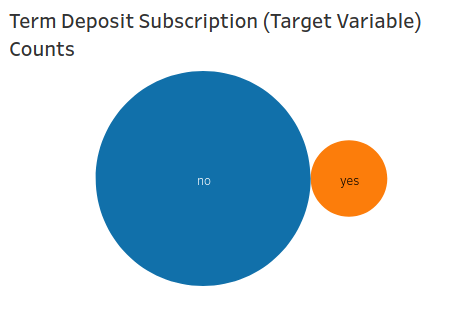
The circles’ sizes represents the value counts of each class. Clearly there’s extreme class imbalance. This will be taken care of in the preprocessing section.
Preprocessing
Preprocessing involves the following steps:
Imputing null values
Missing values need to be handled because they can lead to wrong predictions and can also cause a high bias for any given model being used.
The categorical features will be imputed with the column mode, the discrete numerical features with the column median and the continuous numerical features with the column mean.
Treating outliers
Outliers are a problem for many machine learning algorithms because they can cause missing of important insights or contort real results which eventually results to less accurate models.
The outliers will be clipped with the 10th and 90th percentiles.
Feature Generation
Generating new features from already existing features adds new information to be accessible during the model training and therefore increasing model accuracy.
Scaling numerical variables
Standardizing numerical features with a StandardScaler to remove the differences brought about by different units of measurement.
#class-imbalance #classification #modeling #data-preprocessing #resampling #data analytic