How and Why
Why: Due to the influx of such a vast amount of data and processing power, we will explore how we can predict human traits using just a collection of Facebook Likes. To achieve our results, we will try to replicate the popular paper that analyzed data from the Cambridge Analytica Data Scandal. (Paper here)
How: To build a predictive model, we will utilize the Facebook Ad Categories dataset. Using this, we will attempt to create a user-like sparse matrix where each category corresponds with a rating. (1 represents, the user likes the content. 0 represents, the user does not like the content)
Requirements
- Python 3.8
- Scikit-Learn
- Pandas
- Numpy
Dataset
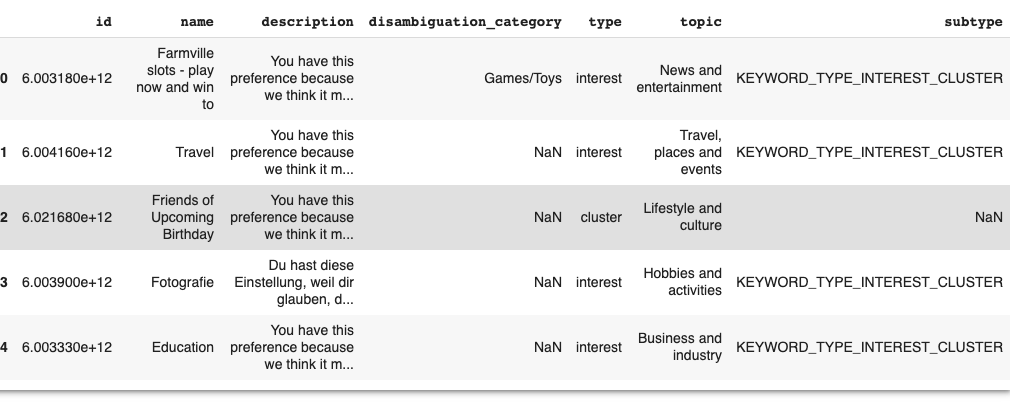
Like any ML/Data Mining project, we will start by analyzing and generating the dataset.
#facebook #data-mining #python #machine-learning #data analysis
1.10 GEEK