In today’s era, everyone is talking about microservices. The journey of the microservice architecture begins with a monolith. In a monolith, we are packing our entire app as a single unit, we are developing it and deploying it as a single app. A big chunk of code in a single repository, which is hard to maintain and scale. In order to handle the problems related to the monoliths, there is a common solution i.e. splitting the monolith in the number of manageable, independent services and scale them separately as and when required. These smaller services are known as microservices.
Let’s take our traditional monolith and see what’s good with it. Let’s say, our monolith has 4 modules — A, B, C, and D. Now whenever A wants to talk to B, it’s very easy. It’s just a function call as A will be able to call a public method of B as they are the part of the same app. But there exists a lot of problems with such a system like:
- If there is a bug in module A and the code is unable to compile. This will bring our entire service down
- If the load on module A is much much greater than module B, we are not able to scale module A independently.
- The release of module A is dependent on the release of module B
Therefore, it is suggested splitting our monoliths into smaller services.
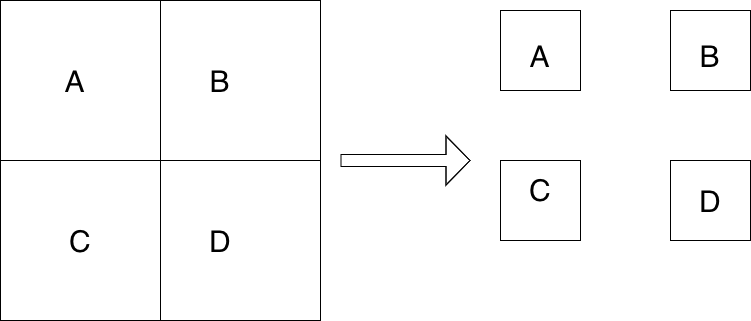
Figure 1 — Splitting a monolith into smaller services
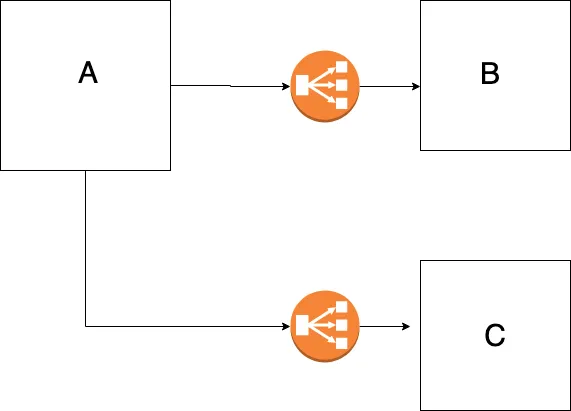
But in a distributed setup, we have to face many challenges like how will module A gonna interact with module B.
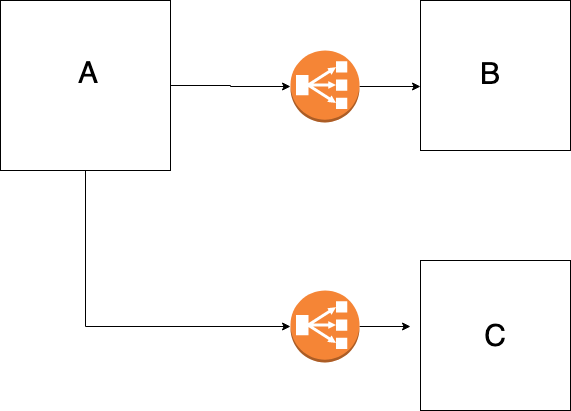
Figure 2 — Services communicating via a load balancer
#software-architecture #software-engineering #service-mesh #programming #microservices