In this article, we would — state the appropriate criteria for applying the k-fold cross-validation on an imbalanced class distribution problem; and demonstrate how to implement that in python through Jupyter notebook.
This article will cover the following sections:
A Quick Overview Of The K-Fold Cross Validation
Overview Of Data Source
Rules For Correctly Applying The K-Fold Cross Validation On An Imbalanced Class Distribution Model
How To Apply A K-Fold Cross Validation On An Imbalanced Classification Problem In Python
A Quick Overview Of The K-Fold Cross-Validation
It is statistically unreliable to evaluate the performance of a model just once. It is best to repeat the performance evaluation multiple times to create a distribution of performance evaluation values, and then take a summary statistics (say mean and standard deviation)of the distribution. This ensures we get a true representative estimate of the true performance value of the model, together with the variance. This concept is called repeated random sampling.
The **k-fold cross-validation **(k-fold cv)makes use of the repeated random sampling technique to evaluate model performance by dividing the data into 5 or 10 equal folds and thereafter evaluating the performance of the model on each fold. Specifically, it evaluates the performance of a model by carrying out the following ordered steps:
- Shuffle the main data,
- Divide the main data into k groups without replacement,
- Take the first group as a test data, and the remaining k-1 group as a training data set, then perform model performance evaluation,
- Repeat step 3 above, for every other group (second group, third group… kth group) E.g Take the second group as a test data, and the remaining k-1 group as training data set, then perform model performance evaluation,
- Score model performance( on accuracy, roc_auc, etc)for each k-fold cross-validation evaluation, and
- Take the mean and variance of the distribution of scores to estimate the overall performance of the model.
The figure below highlights the number of cross-validation evaluations (5 evaluations carried out) carried out on a 5-fold split to evaluate a model performance:
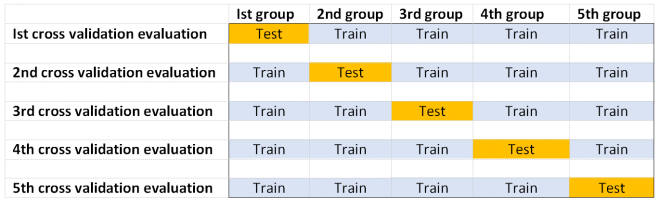
In general and as observed from the figure above, each group of a k group split would be a test group once, and a member of a training data set k-1 times during model performance cross-validation evaluation.
#machine-learning #model #how-to #data-science #evaluation #deep learning
