As one of the most popular classic machine learning algorithm, the Decision Tree is much more intuitive than the others for its explainability. Let’s consider the following conversation.
Jade: “Should we go out running tomorrow?”
Chris: “How about the weather?”
Jade: “Let me check it on my phone. It’s a sunny day!”
Chris: “That sounds good! How about the temperature then?”
Jade: “Hmmm… 35 degrees”
Chris: “Oh, it’s too hot. I would prefer to go swimming in an indoor swimming pool.”
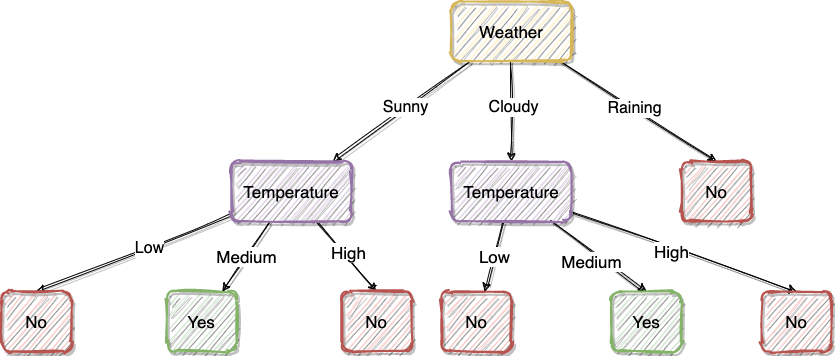
We make many decisions in our life. If we think about why we made those decisions, most of the time there is a “decision tree” behind it as shown in the above picture. That’s why the decision tree is probably the most intuitive machine learning method which is very close to the human mind.
Building Blocks of a Decision Tree
Photo by PublicDomainPictures on Pixabay
How is a Decision Tree built as a machine learning model? There are several different popular algorithms to build a Decision Tree, but they must include two steps: Constructing a tree and Pruning the tree.
Constructing a Decision Tree
To construct a Decision Tree, an algorithm needs to generate three types of nodes:
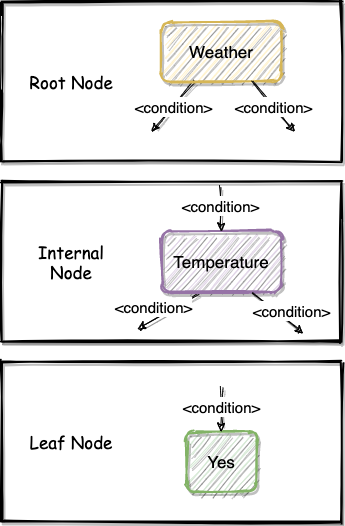
- Root Node: A Decision Tree will have only one root node, which is on the top of the tree.
- Internal Node: These nodes are intermediate between their parent nodes and child nodes.
- Leaf Node: These nodes will NEVER have child nodes, and they are actually the “decision” made by the Decision Tree.
#algorithms #data-mining #data-science #decision-tree #machine-learning