Data bias in machine learning is a type of error in which certain elements of a dataset are more heavily weighted and/or represented than others. A biased dataset does not accurately represent a model’s use case, resulting in skewed outcomes, low accuracy levels, and analytical errors.
In general, training data for machine learning projects has to be representative of the real world. This is important because this data is how the machine learns to do its job. Data bias can occur in a range of areas, from human reporting and selection bias to algorithmic and interpretation bias. The image below is a good example of the sorts of biases that can appear in just the data collection and annotation phase alone.
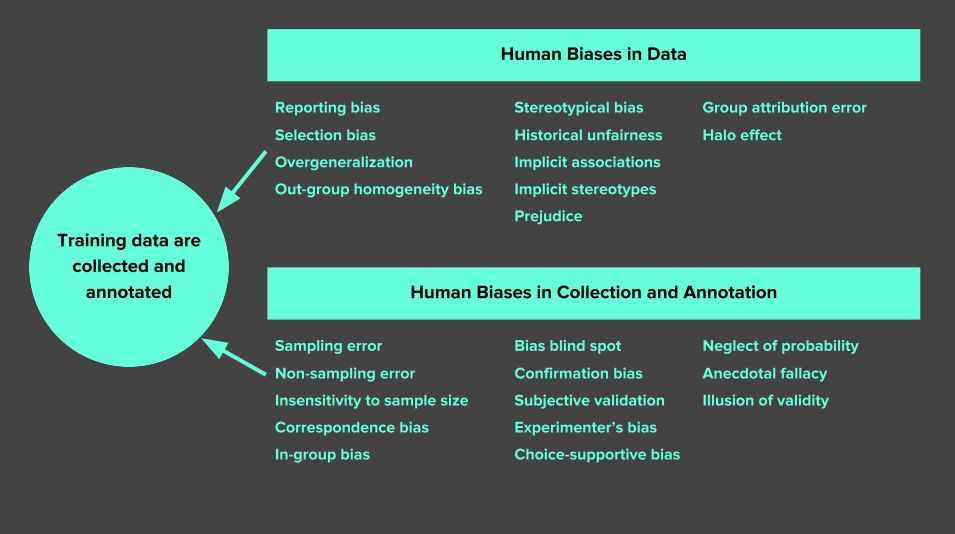
Resolving data bias in machine learning projects means first determining where it is. It’s only after you know where a bias exists that you can take the necessary steps to remedy it, whether it be addressing lacking data or improving your annotation processes. With this in mind, it’s extremely important to be vigilant about the scope, quality, and handling of your data to avoid bias where possible. This effects not just the accuracy of your model, but can also stretch to issues of ethics, fairness, and inclusion.
Below, I’ve listed seven of the most common types of data bias in machine learning to help you analyze and understand where it happens, and what you can do about it.
(If you need more information on data collection and data labeling for machine learning projects, here’s a link to learn more about training data for machine learning before reading the rest of the article.)
#machine-learning #learn-machine-learning #data-science #data-analysis #ai #ai-applications #artificial-intelligence #hackernoon-top-story
