As a keen learner of Machine Learning, I’ve always been curious about different approaches of building an intelligent system. I firmly do believe that **_‘Machine Learning as a field’ _**expects us to explore and try different approaches that might not have gained any recognition before. Since my areas of interest are Recommendation System, NLP(Natural Language Processing) and Programming, I’ve got to coalesce these areas and come up with some unique approaches.
There are various methods for building a recommendation system and when we get along with building one, we’ll eventually find that items need to be compared at some point. Since finding items similarities with Item based collaborative filtering has probably been hackneyed, I’ve tied the concept of NLP & Recommendation System to find items similarities.
Using word embeddings as a base concept
I assume that you’re familiar with word embeddings, if not click on the link below or else be ok with lifting a burden of regret your entire life.
If you’ve read the article, you can see that word embeddings are generated by training a neural network on a corpus (sequence of words). Aligning this very concept, we can find item embeddings in the same way. I will be explaining the approach below.
How item embeddings are generated?
Step 1:- Generation of Item Corpus
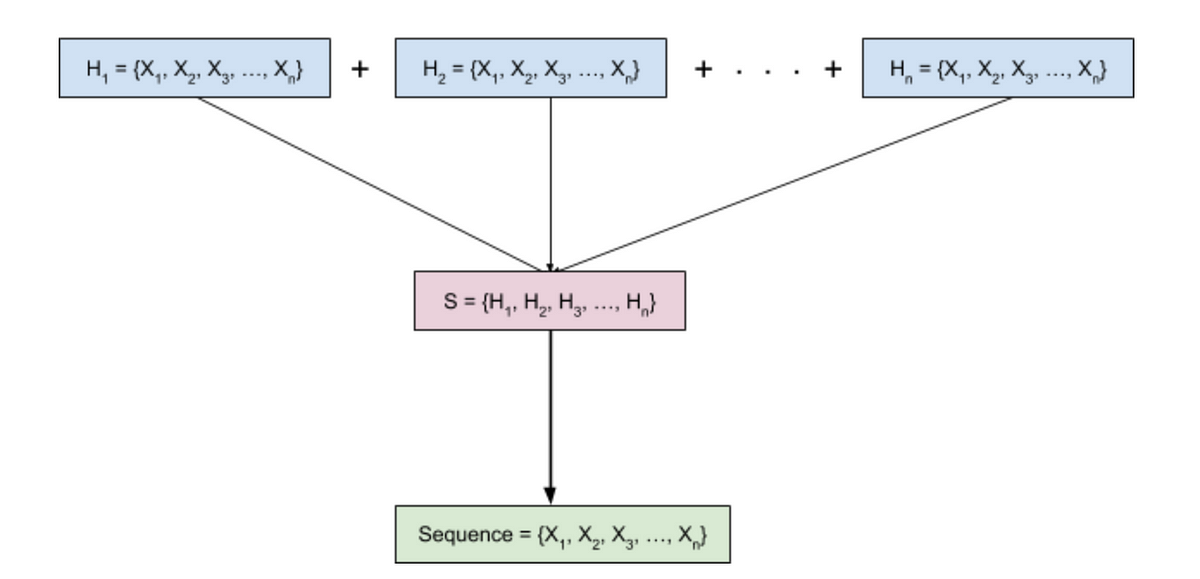
A user interaction forms a sequence over time, which is indicated by** Hn = {X1, X2, . . . , Xn}**. Xn denotes the items. So, the combination of interaction patterns of different users forms a long sequence (item corpus), denoted by S = {H1, H2, H3, . . . , Hn }, where n indicates the number of users.
#machine-learning #item-similarity #recommendation-system #item-embeddings #nlp