With Performance Comparison Analysis and Guided Example of Animated 3D Wireframe Plot
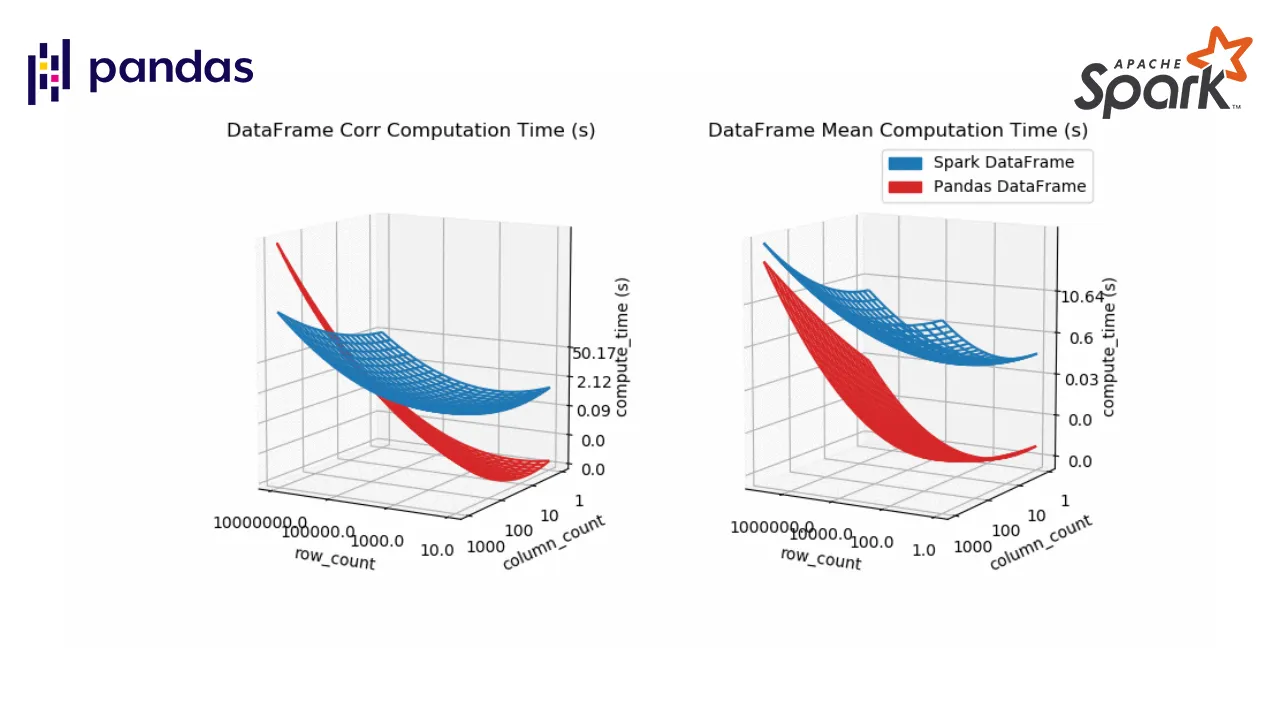
Python is famous for its vast selection of libraries and resources from the open-source community. As a Data Analyst/Engineer/Scientist, one might be familiar with popular packages such as Numpy, Pandas, Scikit-learn, Keras, and TensorFlow. Together these modules help us extract value out of data and propels the field of analytics. As data continue to become larger and more complex, one other element to consider is a framework dedicated to processing Big Data, such as Apache Spark. In this article, I will demonstrate the capabilities of distributed/cluster computing and present a comparison between the Pandas DataFrame and Spark DataFrame. My hope is to provide more conviction on choosing the right implementation.
Pandas DataFrame
Pandas has become very popular for its ease of use. It utilizes DataFrames to present data in tabular format like a spreadsheet with rows and columns. Importantly, it has very intuitive methods to perform common analytical tasks and a relatively flat learning curve. It loads all of the data into memory on a single machine (one node) for rapid execution. While the Pandas DataFrame has proven to be tremendously powerful in manipulating data, it does have its limits. With data growing at an exponentially rate, complex data processing becomes expensive to handle and causes performance degradation. These operations require parallelization and distributed computing, which the Pandas DataFrame does not support.
Introducing Cluster/Distribution Computing and Spark DataFrame
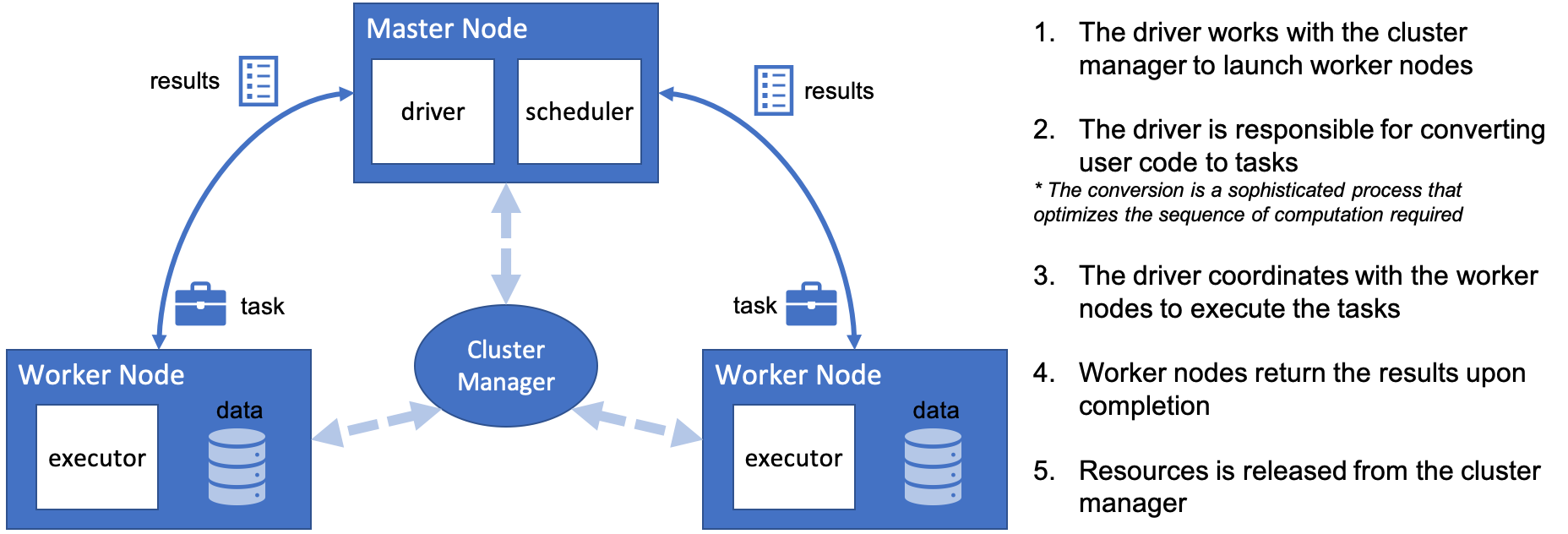
Apache Spark is an open-source cluster computing framework. With cluster computing, data processing is distributed and performed in parallel by multiple nodes. This is recognized as the MapReduce framework because the division of labor can usually be characterized by sets of the map, shuffle, and reduce operations found in functional programming. Spark’s implementation of cluster computing is unique because processes 1) are executed in-memory and 2) build up a query plan which does not execute until necessary (known as lazy execution). Although Spark’s cluster computing framework has a broad range of utility, we only look at the Spark DataFrame for the purpose of this article. Similar to those found in Pandas, the Spark DataFrame has intuitive APIs, making it easy to implement.
#pandas dataframe vs. spark dataframe: when parallel computing matters #pandas #pandas dataframe #pandas dataframe vs. spark dataframe #spark #when parallel computing matters