1. What do you understand by Natural Language Processing?
Natural Language Processing is a field of computer science that deals with communication between computer systems and humans. It is a technique used in Artificial Intelligence and Machine Learning. It is used to create automated software that helps understand human spoken languages to extract useful information from the data it gets in the form of audio. Techniques in NLP allow computer systems to process and interpret data in the form of natural languages.
If you want to learn Natural Language Processing then go through the following tutorial:
2. What are stop words?
Stop words are said to be useless data for a search engine. Words such as articles, prepositions, etc. are considered as stop words. There are stop words such as was, were, is, am, the, a, an, how, why, and many more. In Natural Language Processing, we eliminate the stop words to understand and analyze the meaning of a sentence. The removal of stop words is one of the most important tasks for search engines. Engineers design the algorithms of search engines in such a way that they ignore the use of stop words. This helps show the relevant search result for a query.
3. List any two real-life applications of Natural Language Processing.
Two real-life applications of Natural Language Processing are as follows:
- Google Translate: Google Translate is one of the famous applications of Natural Language Processing. It helps convert written or spoken sentences into any language. Also, we can find the correct pronunciation and meaning of a word by using Google Translate. It uses advanced techniques of Natural Language Processing to achieve success in translating sentences into various languages.
- Chatbots: To provide a better customer support service, companies have started using chatbots for 24/7 service. Chatbots helps resolve the basic queries of customers. If a chatbot is not able to resolve any query, then it forwards it to the support team, while still engaging the customer. It helps make customers feel that the customer support team is quickly attending them. With the help of chatbots, companies have become capable of building cordial relations with customers. It is only possible with the help of Natural Language Processing.

4. What is TF-IDF?
TFIDF or Term Frequency-Inverse Document Frequency indicates the importance of a word in a set. It helps in information retrieval with numerical statistics. For a specific document, TF-IDF shows a frequency that helps identify the keywords in a document. The major use of TF-IDF in NLP is the extraction of useful information from crucial documents by statistical data. It is ideally used to classify and summarize the text in documents and filter out stop words.
TF helps calculate the ratio of the frequency of a term in a document and the total number of terms. Whereas, IDF denotes the importance of the term in a document.
The formula for calculating TF-IDF:
TF(W) = (Frequency of W in a document)/(The total number of terms in the document)
IDF(W) = log_e(The total number of documents/The number of documents having the term W)
When TF*IDF is high, the frequency of the term is less and vice versa.
Google uses TF-IDF to decide the index of search results according to the relevancy of pages. The design of the TF-IDF algorithm helps optimize the search results in Google. It helps quality content rank up in search results.
If you want to know more about ‘What is Natural Language Processing?’ you can go through this Natural Language Processing Using Python course!
5. What is Syntactic Analysis?
Syntactic analysis is a technique of analyzing sentences to extract meaning from it. Using syntactic analysis, a machine can analyze and understand the order of words arranged in a sentence. NLP employs grammar rules of a language that helps in the syntactic analysis of the combination and order of words in documents.
The techniques used for syntactic analysis are as follows:
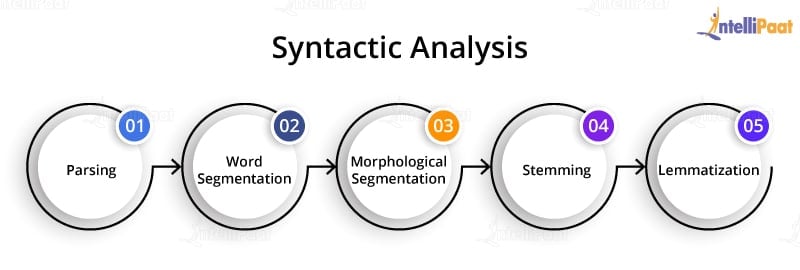
- Parsing: It helps in deciding the structure of a sentence or text in a document. It helps analyze the words in the text based on the grammar of the language.
- Word segmentation: The segmentation of words segregates the text into small significant units.
- Morphological segmentation: The purpose of morphological segmentation is to break words into their base form.
- Stemming: It is the process of removing the suffix from a word to obtain its root word.
- Lemmatization: It helps combine words using suffixes, without altering the meaning of the word.
6. What is Semantic Analysis?
Semantic analysis helps make a machine understand the meaning of a text. It uses various algorithms for the interpretation of words in sentences. It also helps understand the structure of a sentence.
Techniques used for semantic analysis are as given below:
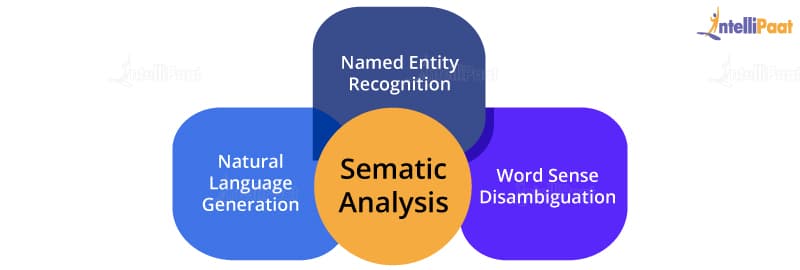
- Named entity recognition: This is the process of information retrieval that helps identify entities such as the name of a person, organization, place, time, emotion, etc.
- Word sense disambiguation: It helps identify the sense of a word used in different sentences.
- Natural language generation: It is a process used by the software to convert the structured data into human spoken languages. By using NLG, organizations can automate content for custom reports.
If you want to learn Artificial Intelligence then enroll in Artificial Intelligence Training now!
7. What is NLTK?
NLTK is a Python library, which stands for Natural Language Toolkit. We use NLTK to process data in human spoken languages. NLTK allows us to apply techniques such as parsing, tokenization, lemmatization, stemming, and more to understand natural languages. It helps in categorizing text, parsing linguistic structure, analyzing documents, etc.
A few of the libraries of the NLTK package that we often use in NLP are:
- SequentialBackoffTagger
- DefaultTagger
- UnigramTagger
- treebank
- wordnet
- FreqDist
- patterns
- RegexpTagger
- backoff_tagger
- UnigramTagger, BigramTagger, and TrigramTagger
8. How to tokenize a sentence using the nltk package?
Tokenization is a process used in NLP to split a sentence into tokens. Sentence tokenization refers to splitting a text or paragraph into sentences.
#interview #interview-questions #nlp-interview
