Google has published a new way of pre-training a language model which is augmented using a knowledge retrieval mechanism, that looks up existing knowledge from an external Wikipedia corpus. This makes the outputs the trained language model generates more fact-based and vast. It uses masked language modeling transformers for training and learns to retrieve and attend from millions of Wiki documents.
There are 5 sections to this article:
- Intro to Knowledge Base
- Intro to REALM
- Training Process
- Knowledge Retrieval In Detail
- Future Speculation
Recently OpenAI released GPT-3 which is trained using 175 billion parameters to generate some really amazing results, you can read more here. Previously Google themselves had released transformer-based models like Bert and T5 which have shown to be useful for a variety of tasks.
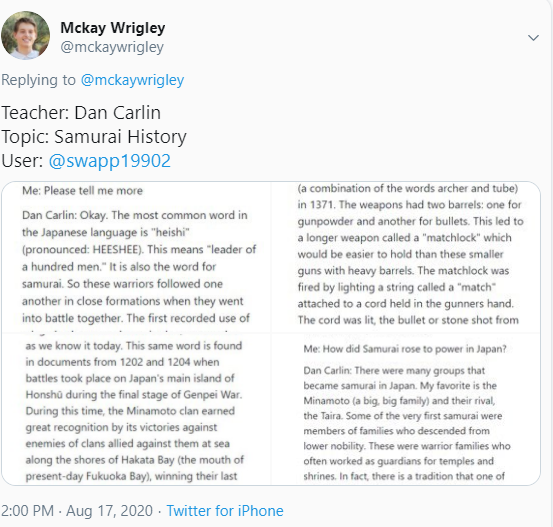
I have been playing with https://learnfromanyone.com/ which is an app in development and using GPT3 api. Mckay Wrigley posted some conversations users have with the app. For instance I am learning about Samurai history from Dan Carlin himself. (or the GPT3 actor Dan Carlin) Which is fun because I don’t know much about Japanese history and it’s a fun and unique way to learn only possible because of GPT-3! But as Brady on twitter commented a valid concern, is what GPT-3 saying accurate?. Currently there is no way to fact-check if what GPT-3 is saying is accurate with an external source. So anyone with some cursory knowledge on the topics can point out the inaccuracies, which is a flaw for the current GPT-3 based systems.
#deep-learning #machine-learning #artificial-intelligence #google #gpt-3
