In the course of the last years the interest in Data Science and Machine Learning has continuously increased. Thanks to libraries like Scikit-Learn, it is getting easier and easier to apply machine learning algorithms. However, in my experience, one thing is often overlooked, namely how to successfully bring such models into production.
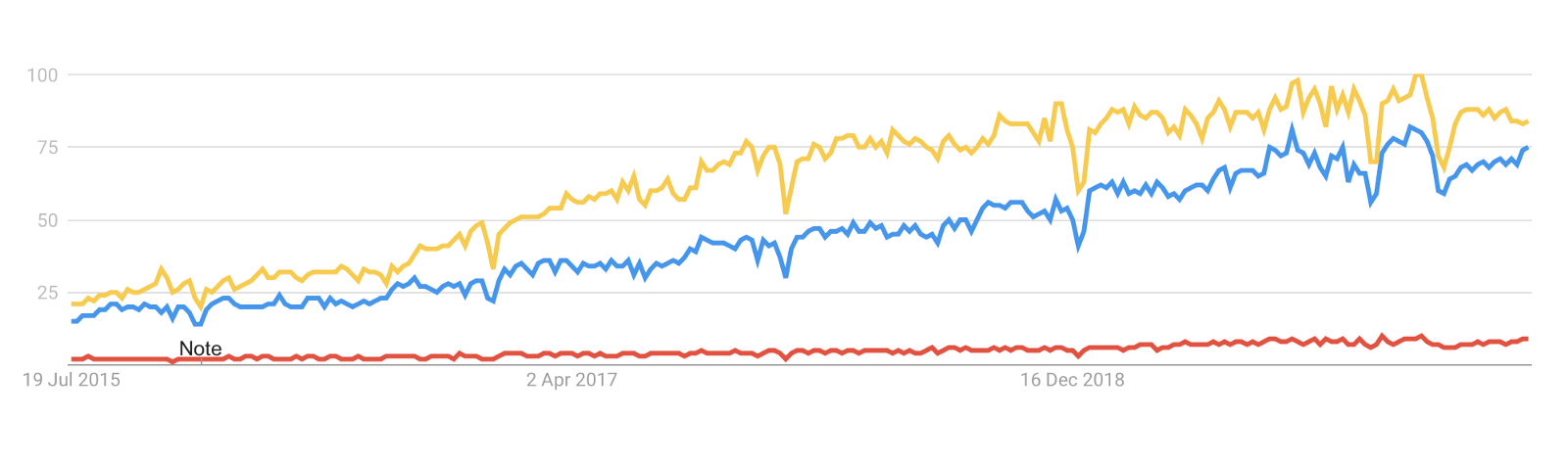
While the interest in Machine Learning (yellow) and Data Science (blue) is growing steadily, Data Engineering (red), although equally important, remain relatively unnoticed
Bringing Machine Learning models requires data pipelines that transport the data to the model and get the results to where they are needed and where they can add value. Accordingly, every data scientist also needs data engineering skills to extract added value from a model. In the following, I would therefore like to present a simple pipeline, which enables exactly this: bringing models into production.
The pipeline consists of four individual parts: the input, the model, the output and a trigger. After the trigger starts the pipeline, the input data required for the model is loaded. The trigger can transmit information, for example a user id, so that only the data relevant for this user is loaded. The model is applied to this data and a result is calculated. The type of model does not play a role here. You can use any of the common machine learning libraries or even completely different methods to take advantage of the data. The result is finally stored in the output database. Now let’s jumpy into the actual implementation. If interested, you can clone the code from my GitHub.
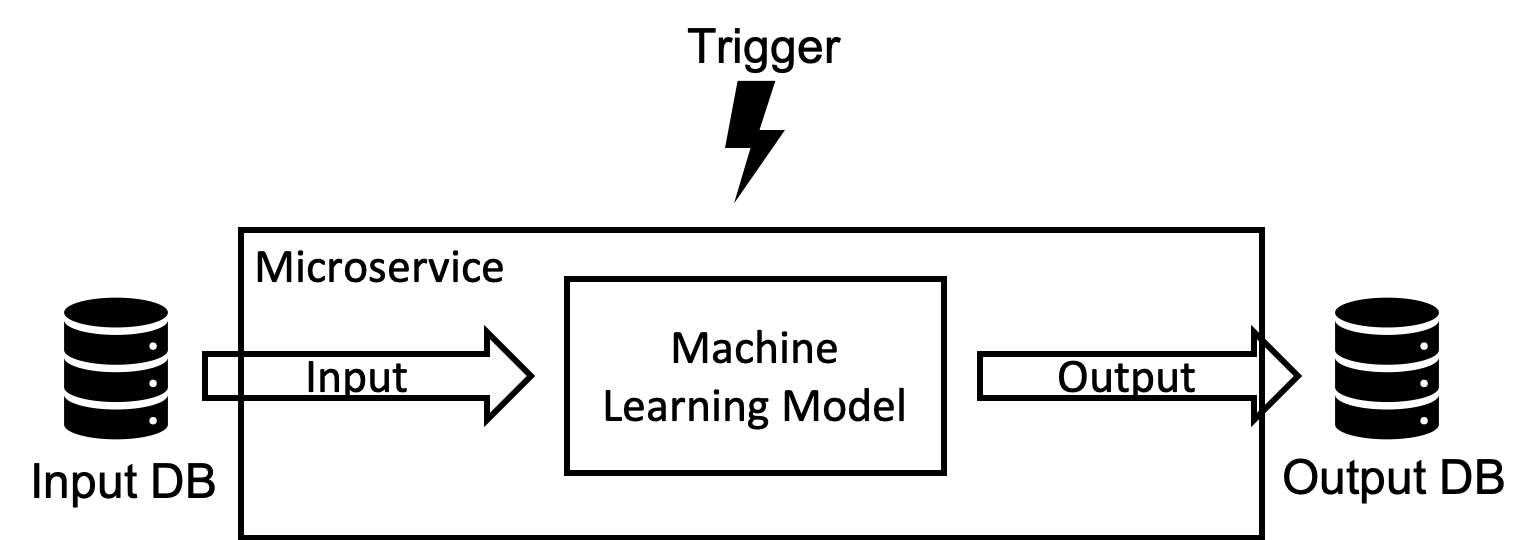
Once triggered, the service get some input data, next the model is applied to the data and finally the result is stored in the output database.
For the micro service I use Flask. This allows to create an API to trigger the pipeline. I also make use of dependency injection (DI). Although DI is not as common in Python as in other languages, it is a very useful concept. Especially when testing, it is a great help. In case you are not yet familiar with DI, this article provide a great explanation. The two database I’m going to use for this post, are BigQuery and a PostgreSQL hosted on AWS. This might be an unlikely set-up, but it certainly helps to demonstrate the flexibility of the data pipeline I propose.
The Flask application is generated in app.py. Here a route called /model is created. If this endpoint is called and a user id is passed, the pipeline starts. The endpoints acts as the trigger. The method underlying the route has three injections, indicated by the injection decorator. These three classes represent the input, the model and the output. The actual implementation of the classes is not important as long as the retriever class has a get, the model class has an apply and the writer class has a write method.
The create_app method creates the Flask app. The keyword argument set the specific classes that are injected per default. When it comes to testing the pipeline, you can easily change these by passing other (mock) classes to create_app. I cover the testing here.
#machine-learning #data-pipeline #python #data-science #data-engineering #data analysis
