Introduction
Approximately 40 million used vehicles are sold each year. Effective pricing strategies can help any company to efficiently sell its products in a competitive market and making profit.
In the automotive sector, pricing analytics play an essential role for both companies and individuals to assess the market price of a vehicle before putting it on sale or buying it.
There are two main goals I want to achieve with this Data Science Project. First, to estimate the price of used cars by taking into account a set of features, based on historical data. Second, to get a better understanding on the most relevant features that help determine the price of a used vehicle.
Data
The data that will be used for this project is accessible at Kaggleandhas been scraped from Craigslist, the world’s largest collection of used vehicles for sale.
The Database consists of 423,857 rows and 25 features, one of which will be the continuous dependent variable (“price”) that we want to predict.
Methodology
EDA
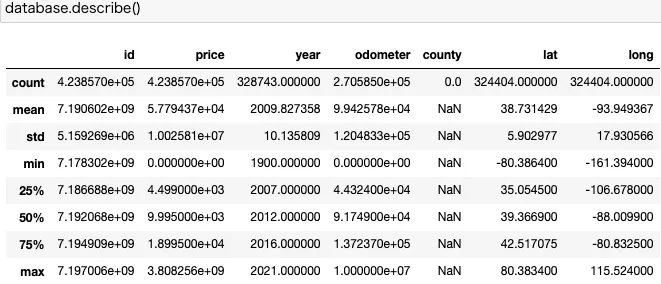
The numerical features play a big role in this Regression model, so it is important to understand well how are they distributed in the Database.
Our focus will be “price”, “year” and “odometer”. As shown in the picture above, there is a big difference between both the maximum value/minimum value and the percentiles for each of these three features. This is an indicator of the presence of outliers, which can greatly hinder the performance of our model. They will be handled later.
#machine-learning #regression #python #vehicles #random-forest #data science