Machine learning is a growing field in artificial intelligence. It aims to provide computer systems with the capability to learn patterns from data and use the experience to make predictions without any direct human intervention.
AndreyBu, who is an experienced machine learning expert from Germany and likes to teach other people his skills, says that “Machine learning is beneficial because it gives us the opportunity to train algorithms to make decisions automatically, something which is usually manually demanding and time consuming.”
In this article, we’ll illustrate a simple classification machine learning algorithm in Python3. We’ll use Scikit-learn, which is a simple, versatile, and open source machine learning framework for Python applications.
Also, we’ll use the Iris flower data set, which is a popular data set that can be used to understand the concepts of machine learning.
Understanding the problem and data
The Iris flower data set, which comes incorporated in Scikit-learn, consists of a set of 150 records. It contains three species of flowers—setosa (labelled 0), versicolor (labelled 1), and virginica (labelled 2)—which have the following numeric attributes (in centimeters):
- Petal width
- Petal length
- Sepal width
- Sepal length
The objective of our machine learning algorithm will be to predict the species of the flowers according to those characteristics. Our model will be trained to learn patterns from the data set based on those features.
Let’s start getting our hands dirty (we are going to use the Anaconda Python distribution).
The Iris data set comes with Scikit-learn and we can simply load it as follows.
from sklearn import datasets
Let’s see if we can get some characteristics of the iris flowers from the data set.
iris = datasets.load_iris()
digits = datasets.load_digits()
It’s important to note that a dataset is a dictionary-like object which keeps all the information about the data. This data is kept in the .data key (an array list).
And, when handling supervised problems like this one, some responses can be kept in the .target list.
For example, appertaining to the digits dataset, we can use digits.data to understand the characteristics for categorizing the digits samples.
Here is the code and the output.
print(digits.data)

Also, digits.target provides us with more visibility on what we intend to learn.
print(digits.target)

We can also peek at the data using iris.data (giving array of data) and iris.target (giving array of labels).
You’ll notice that every entry has four attributes.
iris.data

iris.target

iris.target_names will give us an array of the names of the labels; that is, the three flower species in the data set.
iris.target_names
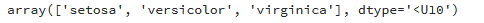
Furthermore, we can also use a box plot to generate a visual representation of the data set.
It will show us how our data is scattered over the plane; using their quartiles.
Here is the code.
import seaborn as sns
iris_data = iris.data #variable for array of the data
iris_target = iris.target #variable for array of the labels
sns.boxplot(data = iris_data,width=0.5,fliersize=5)
sns.set(rc={'figure.figsize':(1,10)})
Here is the output.

Here is how the data is represented on the horizontal axis.
- 0 is sepal length (centimeters)
- 1 is sepal width (centimeters)
- 2 is petal length (centimeters)
- 3 is petal width (centimeters)
Training and testing
After understanding the details of our data, we can now use an algorithm for training a prediction model. As such, we’ll need to split our data into two sets: training and testing sets.
By training on a section of the data and performing tests on another set of data, which the machine learning model has never interacted with, it assists us to ensure that our algorithm can identify patterns in the dataset, which will improve the accuracy of the predictions.
In this case, we’ll keep the last 15 sets of data for testing and leave the rest for training. Consequently, we’ll train the algorithm based on the training set of the data and predict based on the testing set of the data.
Let’s see some code on how to do that.
import numpy as np
from sklearn import tree
iris_test_ids = np.random.permutation(len(iris_data)) #randomly splitting the data set
#splitting and leaving last 15 entries for testing, rest for training
iris_train_one = iris_data[iris_test_ids[:-15]]
iris_test_one = iris_data[iris_test_ids[-15:]]
iris_train_two = iris_target[iris_test_ids[:-15]]
iris_test_two = iris_target[iris_test_ids[-15:]]
iris_classify = tree.DecisionTreeClassifier()#using the decision tree for classification
iris_classify.fit(iris_train_one, iris_train_two) #training or fitting the classifier using the training set
iris_predict = iris_classify.predict(iris_test_one) #making predictions on the test dataset
Viewing the results
Because we are splitting the data set randomly and the classifier is training after each iteration, we may get different levels of accuracy every time the code is run.
Here is the code for viewing the results.
from sklearn.metrics import accuracy_score
print(iris_predict) #lables predicted (flower species)
print (iris_test_two) #actual labels
print (accuracy_score(iris_predict, iris_test_two)*100) #accuracy metric
Here is the output.

The first line on the above output gives the labels of the testing data; that is, the flower species based on the predictions of the classifier.
The second line gives the actual species contained in the data set. And, the last line gives the precision %. In this case, we got an accuracy level of 86.67%.
Not very bad!
Conclusion
Here is the code for the entire project.
from sklearn import datasets
import seaborn as sns
import numpy as np
from sklearn import tree
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
digits = datasets.load_digits()
print(digits.data)
print(digits.target)
print(iris.data)
print(iris.target)
print(iris.target_names)
iris_data = iris.data #variable for array of the data
iris_target = iris.target #variable for array of the labels
sns.boxplot(data = iris_data,width=0.5,fliersize=5)
sns.set(rc={'figure.figsize':(1,10)})
iris_test_ids = np.random.permutation(len(iris_data)) #randomly splitting the data set
#splitting and leaving last 15 entries for testing, rest for training
iris_train_one = iris_data[iris_test_ids[:-15]]
iris_test_one = iris_data[iris_test_ids[-15:]]
iris_train_two = iris_target[iris_test_ids[:-15]]
iris_test_two = iris_target[iris_test_ids[-15:]]
iris_classify = tree.DecisionTreeClassifier()#using the decision tree for classification
iris_classify.fit(iris_train_one, iris_train_two) #training or fitting the classifier using the training set
iris_predict = iris_classify.predict(iris_test_one) #making predictions on the test dataset
print(iris_predict) #labels predicted (flower species)
print (iris_test_two) #actual labels
print (accuracy_score(iris_predict, iris_test_two)*100) #accuracy metric
In this post, we illustrated a simple machine learning project in Python.
To increase your machine learning knowledge, you need to complete such projects.
Better still, you can pick other advanced projects from a site like LiveEduand increase your expertise in machine learning.
#python #machine-learning
