Fine-Tune Large Language Models with Azure Machine Learning
Eversince Nov 2022, as Microsoft and OpenAI accounted ChatGTP the LLM space has been revolutionized and democratized. The demand to adopt the technology and apply it to the diverse use cases across the customer space has been overwhelming, to say the least. OpenAI and Microsoft have been leading the way with enterprise-grade solutions in the shape of co-pilots on ChatGPT variants. Azure OpenAI Studio primarily offers SaaS based solutions for Retrieval Augmented Generations (RAG), and based on Prompt engineering, it is unmatched and state of the art.
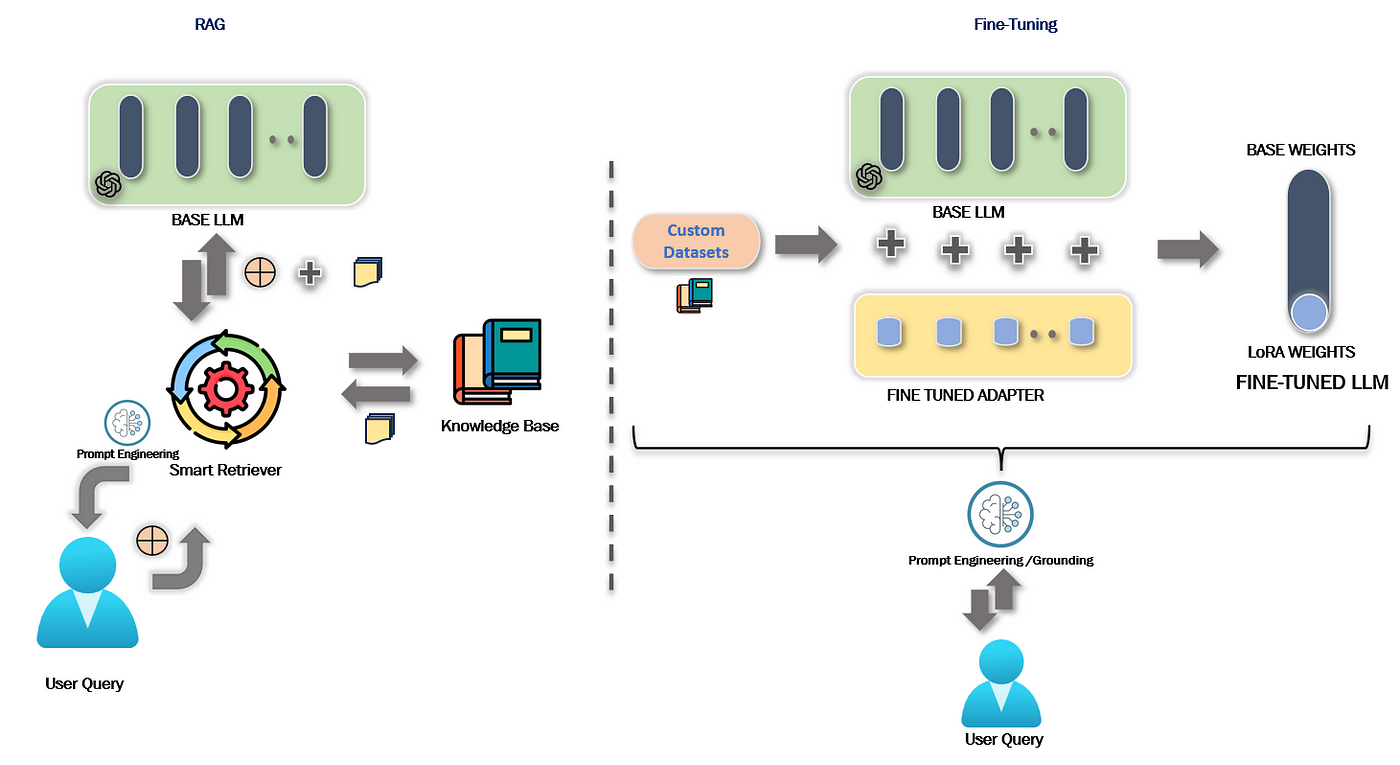
RAG & Fine-Tuning LLMs
Choosing between retrieval augmented generation (RAG) and fine-tuning a large language model depends on various factors. Fine-tuning is suitable when you have a substantial amount of task-specific labeled data and require a deep understanding of a specific domain or complex patterns. However, it can be computationally expensive, time-consuming, and requires significant infra management/operationalization and GPU resources. On the other hand, RAG is advantageous when you have a retrieval corpus available, covering relevant information for the task. It allows leveraging retrieval to find relevant passages for generating responses. RAG is more efficient in terms of resource utilization and provides faster results, making it suitable for applications with limited computational resources, real-time requirements, or low latency needs.
When choosing between these approaches, consider the following factors:
- Data Availability: Fine-tuning requires task-specific labeled data, while RAG leverages a retrieval corpus.
- Task Complexity: Fine-tuning is better for complex tasks, while RAG is more suitable for leveraging existing knowledge and domain expertise.
- Resource Constraints: Fine-tuning requires substantial computational resources, whereas RAG is more efficient in terms of resource utilization.
- Domain Adaptability: RAG is advantageous when relevant information is distributed across a retrieval corpus.
- Latency and Real-time Requirements: RAG provides faster results and low-latency responses compared to fine-tuning.
- IaaS Appetite: Skill/Ability to manage the operationalization infra.
In terms of infrastructure management, fine-tuning a model requires significant compute resources, storage, and time for training. It involves managing the training pipeline, including data preprocessing, model training, and hyperparameter tuning. On the other hand, RAG requires managing the retrieval corpus, indexing it efficiently for fast retrieval, and integrating it with the generation component. Additionally, for both approaches, considerations such as model versioning, deployment, scaling, monitoring, and resource allocation need to be taken into account when managing the infrastructure.
Ultimately, the choice between RAG and fine-tuning depends on your specific use case, available resources, data, task complexity, and performance requirements, infra management appetite. Evaluating these factors will help determine the most suitable approach for your application and guide your infrastructure management decisions.
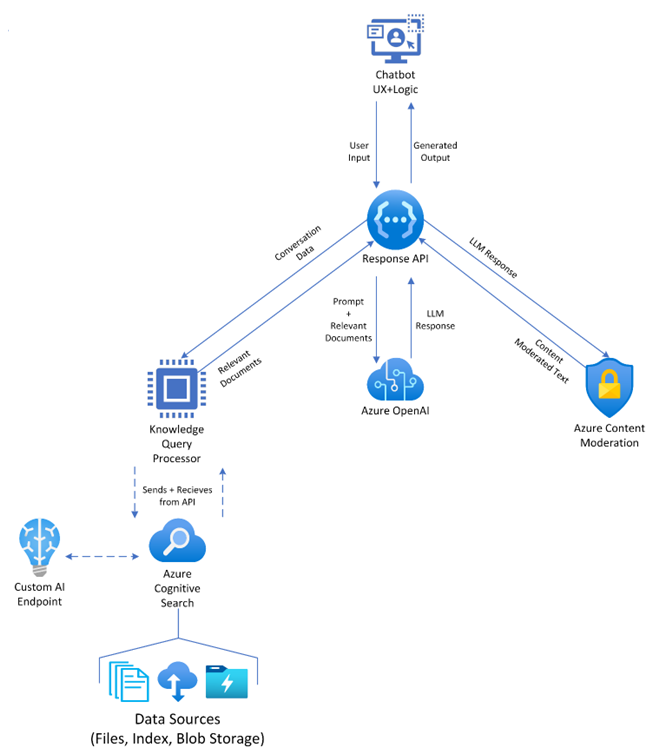
Azure OpenAI — Bring Your Own Data Enables Easy Grounding of GPT Models
However, the demand for tailored solutions in enterprise use cases may necessitate a broader conversation. Can we host a tailored model while owning the IaaS for such? Does Azure enable such? The answer is YES, and that is the topic of this blog.
With full regards to the Azure OpenAI offered solutions, Azure also embraces open source software (OSS).
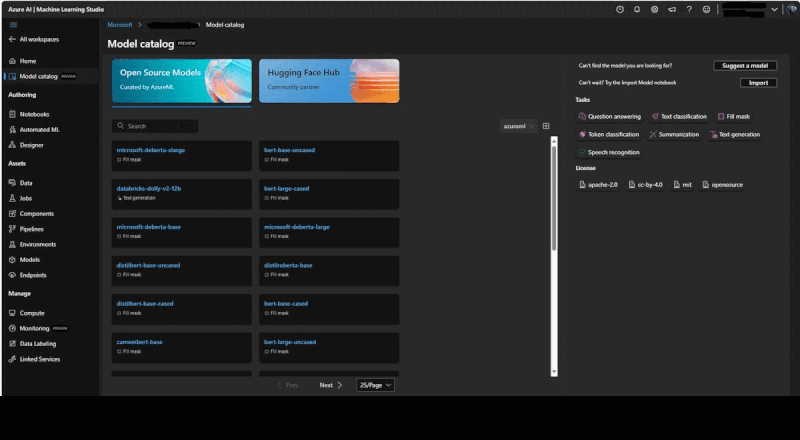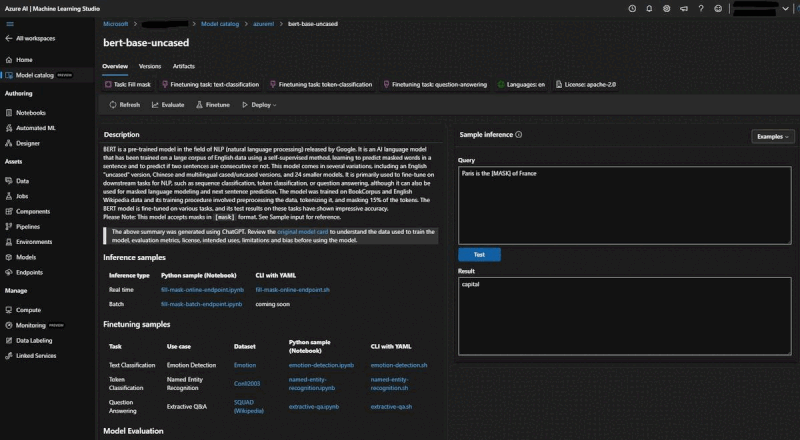
OSS LLM On Azure ML
Albeit it comes with management bottlenecks, using an open-source large language model (LLM) like GPT (Generative Pre-trained Transformer) could offer some flexibility over using a software-as-a-service (SaaS) based ChatGPT solution. It all depends on your business use-case, the choice and needs. Here are some of the advantages of leveraging open source large language models:
- Flexibility and Control: With an open-source LLM, you have complete control over the model. You can customize and fine-tune it according to your specific needs. This flexibility allows you to tailor the model to your application, domain, or business requirements.
- Data Privacy and Security: When using an open-source LLM, you have full control over your data. You don’t have to send your sensitive or proprietary information to a third-party SaaS provider, reducing potential privacy and security concerns. This can be particularly important for industries that deal with sensitive data, such as healthcare or finance.
- Cost-Effectiveness: Open-source LLMs are generally more cost-effective in the long run compared to SaaS solutions. While there may be initial development and infrastructure costs associated with setting up and maintaining the model, you avoid recurring subscription fees that come with SaaS offerings. This can be especially beneficial for organizations with large-scale or long-term usage requirements.
- Customization and Extensibility: Open-source LLMs allow for greater customization and extensibility. You can integrate the model into your existing infrastructure and software stack, modify it to suit specific needs, and extend its functionality with additional modules or features. This level of customization is often limited or restricted in SaaS solutions.
- Community Support and Collaboration: Open-source LLMs benefit from a vibrant community of developers and researchers who contribute to their development, improvement, and bug fixes. This community support can be invaluable in addressing issues, finding solutions, and staying up to date with the latest advancements in language models.
- Independence from Service Providers: By utilizing an open-source LLM, you are not tied to a specific service provider or vendor. This means you are not dependent on the availability or reliability of a particular SaaS platform. You can deploy and run the model on your own infrastructure or choose different cloud providers, giving you more flexibility and freedom.
It’s important to assert that using an open-source LLM also requires technical expertise to set up, maintain, and fine-tune the model. Additionally, SaaS solutions often provide user-friendly interfaces and support services that may be beneficial for non-technical users or organizations with limited resources. Ultimately, the choice between an open-source LLM and a SaaS-based solution depends on your specific needs, resources, and priorities. I would also much emphasize on Economics of Costs.
Unlike Azure OpenAI, this will require us to host/own the OSS instances and manage IaaS. Leading the OSS torch is Hugging Face; It is most notable for its transformers library built for natural language processing applications and its platform that allows users to share machine learning models and datasets.
Hugging Face Transformers is a popular open-source library that provides a high-level interface and a suite of tools for working with various transformer-based models, including large language models (LLMs) like GPT. It simplifies the process of using, fine-tuning, and deploying these models for a wide range of natural language processing (NLP) tasks.
Here are the key features and functionalities of Hugging Face Transformers in the context of LLMs:
- Pre-trained Models: Hugging Face Transformers offers a wide selection of pre-trained LLMs, including GPT, BERT, RoBERTa, Falcon, Dolly and more. These models are already trained on large corpora of text data and can be readily used for a variety of NLP tasks without the need for extensive training from scratch.
- Fine-tuning: The library provides tools and utilities to fine-tune the pre-trained LLMs on custom datasets. Fine-tuning involves further training the LLM on a specific task or domain-specific data to improve its performance. Hugging Face Transformers streamlines the process of adapting these models to specific use cases, allowing developers to achieve better task-specific performance.
- Tokenization: Tokenization is a crucial step in NLP, where input text is split into individual tokens or subwords. Hugging Face Transformers includes tokenization utilities that help convert raw text into tokenized input compatible with the LLMs. This tokenization process ensures that input text is properly represented and fed into the models for processing.
- Model Architecture: The library provides a consistent and easy-to-use interface to interact with LLMs. It abstracts away the complexities of the underlying model architectures and provides a unified API, enabling developers to seamlessly work with different LLMs without having to learn the specific intricacies of each model.
- Task-specific APIs: Hugging Face Transformers offers task-specific APIs, making it straightforward to utilize LLMs for a variety of NLP tasks such as text classification, named entity recognition, question answering, and more. These APIs provide convenient interfaces that handle the intricacies of feeding input data to the models and extracting relevant outputs for specific tasks.
- Model Serving and Deployment: The library provides utilities to serve and deploy LLMs in production environments. This enables developers to integrate LLM-based NLP models into their applications, APIs, or web services, allowing for real-time inference on new inputs.
- Model Hub and Community: Hugging Face hosts the Model Hub, a repository that houses a vast collection of pre-trained LLMs, fine-tuned models, and related resources contributed by the community. This hub serves as a central repository for sharing, exploring, and reusing LLM-based models and workflows.
Hugging Face Transformers simplifies the usage, fine-tuning, and deployment of LLMs by providing a comprehensive set of tools, APIs, and utilities. It abstracts away the complexities of LLMs, making it easier for developers to leverage the power of these models for various NLP tasks. The library’s extensive community support and Model Hub further contribute to its popularity and effectiveness in working with LLMs.
The technique enables optimal loading of these LLM (which are very large in size) into GPU compute memory and further enables fine-tuning with custom datasets specific to one's needs. Highly recommend reading more about it https://huggingface.co/blog/4bit-transformers-bitsandbytes
We aim to fine-tune 3 very popular OSS models from HF.
1.) tiiuae/falcon-40b — Falcon-40B is a 40B parameters causal decoder-only model built by TII and trained on 1,000B tokens of RefinedWeb enhanced with curated corpora. It is made available under the Apache 2.0 license.
tiiuae/falcon-40b · Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.
I highly recommend reading this blog on the details about this model https://huggingface.co/blog/falcon Falcon is a new family of state-of-the-art language models created by the Technology Innovation Institute in Abu Dhabi, and released under the Apache 2.0 license.
2.) databricks/dolly-v2-12b
databricks/dolly-v2-12b · Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.
Databricks’ Dolly is an instruction-following large language model trained on the Databricks machine learning platform that is licensed for commercial use. https://github.com/databrickslabs/dolly
3.) EleutherAI/gpt-neox-20b — On this model I highly recommend reading the paper https://arxiv.org/abs/2204.06745, https://github.com/EleutherAI/gpt-neox
EleutherAI/gpt-neox-20b · Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.
Additional Information on QLoRA: I think
has done an excellent job of explaining the technicalities of this optimization technique. I would leverage his blog to share deeper on — QLoRA, it's a must-read.
Here is a quick comparison and review of each model we have picked for fine-tuning.
Using Azure ML To Fine-Tune LLMs
If you have understood the space and the solutions, this blog aims to provide you with the Cloud Infrastructure in the form of Microsoft Azure for fine-tuning your own version of LLM and further deploying and scaling it for ML-Infused solutions. Azure Machine Learning empowers data scientists and developers to build, deploy, and manage high-quality models faster and with confidence. Azure Machine Learning is a cloud service for accelerating and managing the machine learning project lifecycle.
Compute
Azure ML can provide all the variants of required GPU infrastructure for model fine-tuning.
To begin with we train the “EleutherAI/gpt-neox-20b” model. The GPU compute we have used is a V3 series running CUDA SETUP: Highest compute capability among GPUs : 7.0. A single node Standard_NC6s_v3 (6 cores, 112 GB RAM, 336 GB disk)
When it comes to fine-tuning large language models (LLMs) in machine learning, it’s important to consider the differences between GPUs and CPUs. GPUs, or Graphics Processing Units, are designed for parallel processing and excel at handling multiple computations simultaneously. CPUs, or Central Processing Units, are optimized for sequential tasks and have a smaller number of powerful cores.
To make the most of GPU capabilities for LLM fine-tuning, NVIDIA’s CUDA (Compute Unified Device Architecture) plays a crucial role. CUDA provides a programming model and software framework that allows developers to leverage GPUs for high-performance computing tasks like fine-tuning LLMs. By writing code in languages such as C, C++, or Python and utilizing CUDA libraries and APIs, developers can harness the power of NVIDIA GPUs effectively.
The CUDA runtime, a component of CUDA, enables the execution of CUDA code on NVIDIA GPUs. Different versions of the CUDA runtime, like version 7.0, bring enhancements, features, and bug fixes. Backward compatibility ensures that code written for earlier versions can seamlessly run on newer GPUs, simplifying the deployment and utilization of LLMs in machine learning workflows.
Here is the detailed guidance on understanding it https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
To fine-tune this model the Hugging Face and BitsAndBytes team has put out a Google Colab Notebook with the steps for performing the training. We will leverage the inherent script but undertake its AML compatibility conversion. We will build our AML image based on the PyTorch compatibility reference guide.
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.

Used CUDA version
We will setup the conda environment based on the PyTorch reference and script below.
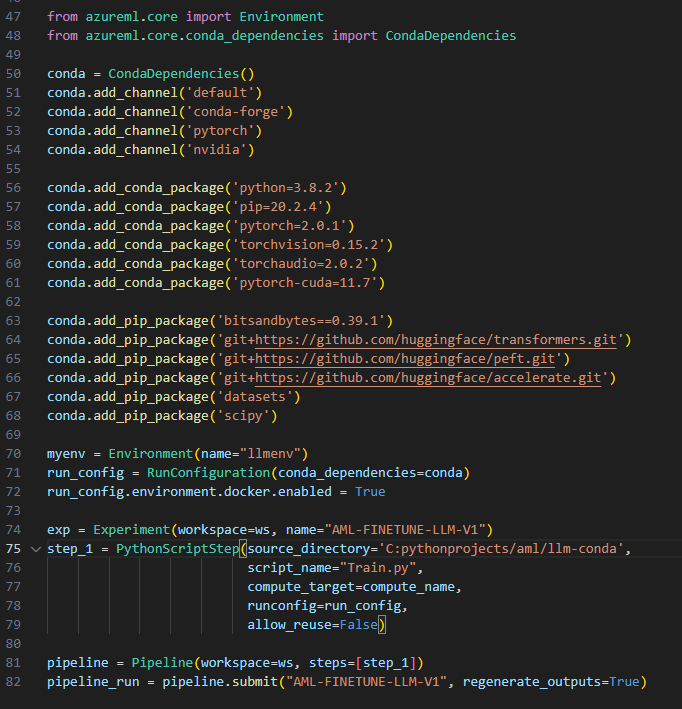
Environment Setup
Azure ML defines containers where your code will run. In the simplest case, you can add custom Python libraries using pip, Conda, or directly via the Azure ML Python SDK. More on Environment setup
Fine-Tuning
GitHub Reference -https://github.com/keshavksingh/finetuning-llm-azureml/tree/main
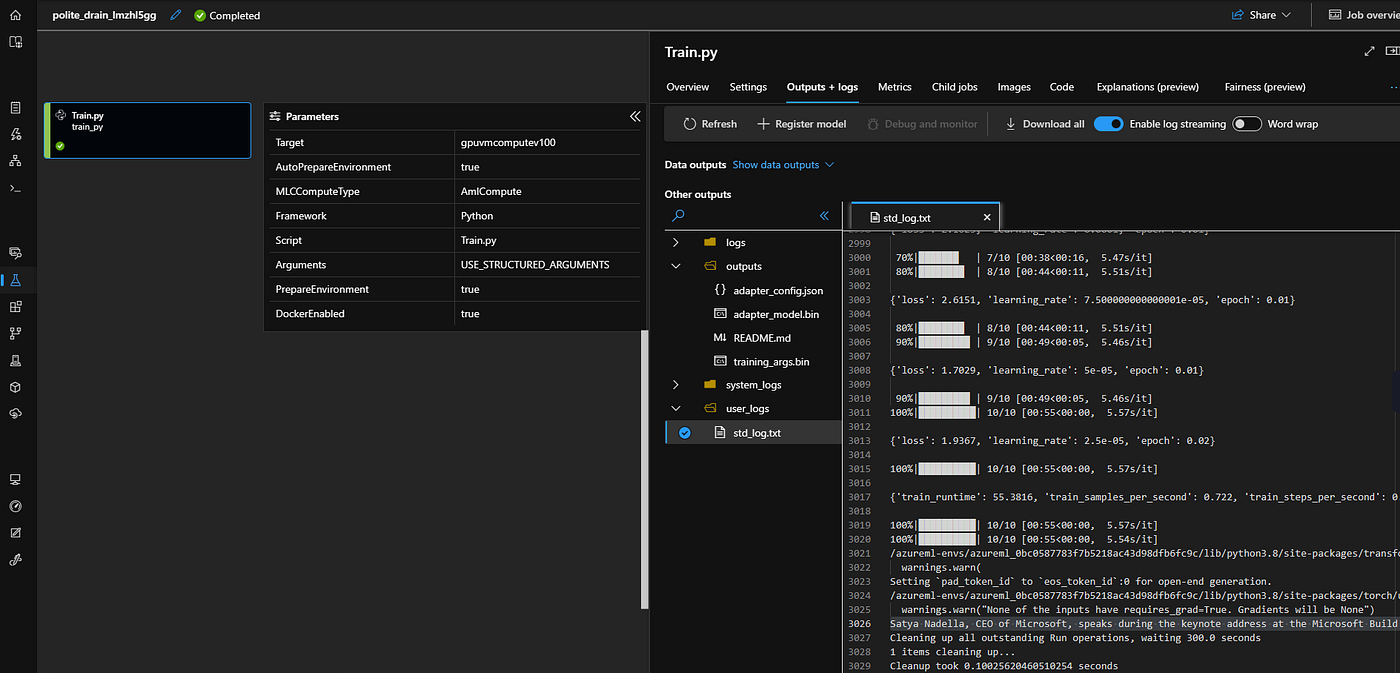
Fine Tuning Result

Test Outcome
The code below has been leveraged from the blogpost.

It loads 20b parameter model with BitsAndBytes based 4bit quantized model for fine tuning. A 40Gb model in half precision. NF4 — normalized float value. We are trying to quantify the model into a lower precision and load it into a smaller GPU machine.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
torch.cuda.is_available()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("We are running on - "+ str(device) +"-----!")
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
import transformers
# needed for gpt-neo-x tokenizer
tokenizer.pad_token = tokenizer.eos_token
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
model_to_save = trainer.model.module if hasattr(trainer.model, 'module') else trainer.model # Take care of distributed/parallel training
model_to_save.save_pretrained("outputs")
trainer.save_model("outputs")
lora_config = LoraConfig.from_pretrained('outputs')
model = get_peft_model(model, lora_config)
text = "Satya Nadella"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Now, considering a simple Deep Neural Network (DNN), the sigmoid activation function would be f(x)=σ(b+W⊤X), familiar with formula: y = wx + b, call w as weight (weight), b as bias (bias), let's review fine-tuning LLMs briefly.
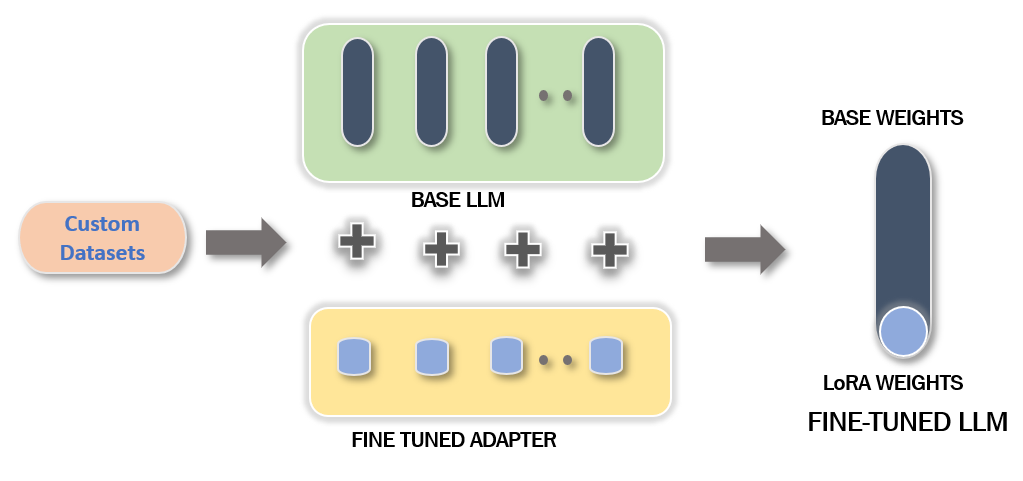
The fine-tuning approach trains additional layers on foundational model (which is considered frozen) based on the custom dataset provided during training. It adds more parameters to the model in the form of adapter configuration which is fractionally smaller compared to the actual LLMs. It helps diverse use-cases with the exact same foundational model efficiently as the produced fine-tuned adapters are only in hundreds of MBs compared to the actual LLMs (which are in Hundreds of GBs). Building on top of LLMs helps achieve fine-tuning with much lower compute power and training time.
The LORA config refers to the configuration settings used in the LORA (Low-Rank Factorization) technique for model fine-tuning. In the context of LLMs, the LORA config determines the specific parameters and settings related to applying low-rank factorization during the fine-tuning process. These settings include the rank reduction factor, threshold values, or other parameters that control the extent and approach of low-rank factorization applied to the LLM model.
While pure 4-bit training, which refers to training LLM models using only 4-bit precision, may not be directly feasible, alternative approaches can still be employed for model training and fine-tuning. Parameter Efficient Fine-Tuning (PEFT) methods, for example, allow for efficient training by leveraging techniques like adapter training. Adapters can be trained on top of pre-trained LLM models, providing a way to incorporate task-specific information without requiring extensive retraining of the entire model. This approach, officially supported by the PEFT library from Hugging Face, allows users to achieve effective fine-tuning while maintaining efficient parameter utilization.
To replicate the results from the paper, users are recommended to consult the training notebook and explore the QLoRA repository. The training notebook provides a step-by-step guide for reproducing the experimental results presented in the paper, facilitating the understanding and implementation of the QLoRA technique. By referring to the QLoRA repository, users can access additional resources, code examples, and documentation specific to the QLoRA optimization technique, helping them replicate and build upon the findings from the paper.

Credits: https://huggingface.co/blog/4bit-transformers-bitsandbytes#can-we-train-4bit8bit-modelsFine Tuning Results
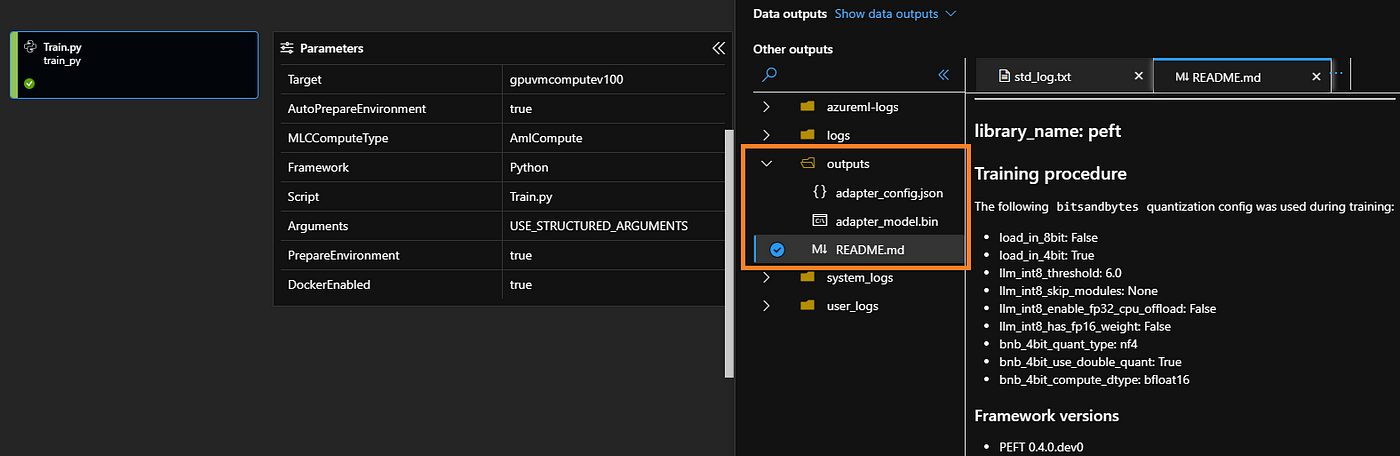
Results: Upon Training
adapter_config.json: This file contains the configuration settings for the trained adapter. It includes information about the architecture, parameters, and other specific details of the adapter. Theadapter_config.jsonfile provides a blueprint for how the adapter was trained and enables the model to understand and utilize the adapter during inference. It is essential for correctly loading and using the trained adapter in subsequent tasks or applications.adapter_model.bin: This file represents the actual weights and parameters of the trained adapter. It contains the learned information and knowledge from the fine-tuning process. Theadapter_model.binfile encapsulates the adapter's trained parameters, which capture task-specific information and are responsible for the adapter's functionality. It is through this file that the trained adapter can be loaded into the LLM model during inference, allowing it to incorporate task-specific capabilities.
Together, the adapter_config.json and adapter_model.bin files enable the integration and utilization of the trained adapter within the LLM model. The config file provides the necessary settings, while the model file holds the learned parameters. When loading the LLM model for inference or further fine-tuning, these files are essential for identifying and incorporating the trained adapter, allowing the model to perform specific tasks or transfer knowledge acquired during fine-tuning.

FineTuned Model
Notice the size of the fine-tuned additional layer to the LLM model is just about 33 MBs.
Here is a simple inferencing of the script performed during the run.
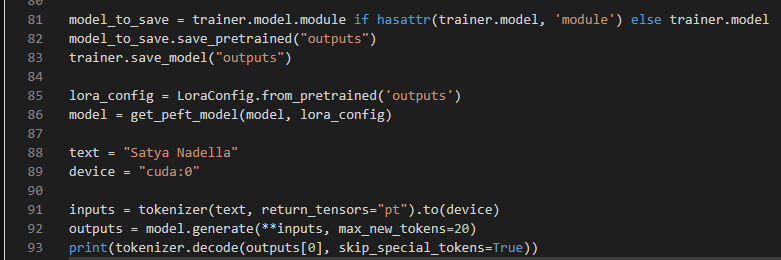
Inferencing
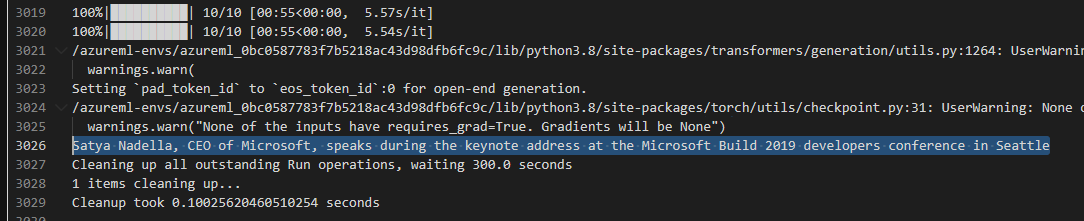
Results
Programming Pitfalls & some critical learning
Ensure the BitsAndBytes compiles with CUDA and detects the right version. You may experience several issues if the setup has incompatibilities, 2 of those are listed below. In my experience, the best option to resolve them are use conda for pytorch and cuda environmental setup. Leverage PIP BitsAndBytes package and use a docker enabled environment on AML.
First Issue Indicates the CUDA deployment error.
AttributeError: /azureml-envs/azureml_f3f7e6c5fb83d94df23933000bf02da3/lib/python3.8/site-packages/bitsandbytes/libbitsandbytes_cpu.so: undefined symbol: cquantize_blockwise_fp16_nf4

Again the CUDA version and LD_LIBRARY_PATH error.

CUDA SETUP: Problem: The main issue seems to be that the main CUDA runtime library was not detected.
CUDA SETUP: Solution 1: To solve the issue the libcudart.so location needs to be added to the LD_LIBRARY_PATH variable
CUDA SETUP: Solution 1a): Find the cuda runtime library via: find / -name libcudart.so 2>/dev/null
CUDA SETUP: Solution 1b): Once the library is found add it to the LD_LIBRARY_PATH: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:FOUND_PATH_FROM_1a
CUDA SETUP: Solution 1c): For a permanent solution add the export from 1b into your .bashrc file, located at ~/.bashrc
CUDA SETUP: Solution 2: If no library was found in step 1a) you need to install CUDA.
CUDA SETUP: Solution 2a): Download CUDA install script: wget https://github.com/TimDettmers/bitsandbytes/blob/main/cuda_install.sh
CUDA SETUP: Solution 2b): Install desired CUDA version to desired location. The syntax is bash cuda_install.sh CUDA_VERSION PATH_TO_INSTALL_INTO.
CUDA SETUP: Solution 2b): For example, "bash cuda_install.sh 113 ~/local/" will download CUDA 11.3 and install into the folder ~/local
CUDA SETUP: Setup Failed!Issues · TimDettmers/bitsandbytes
8-bit CUDA functions for PyTorch. Contribute to TimDettmers/bitsandbytes development by creating an account on GitHub.
During the AML run as the container is built prior to the training run, please review the image being pushed into the Azure Container registry. Ensure all the CONDA paths, CUDA and PIP dependencies are successfully installed and met.
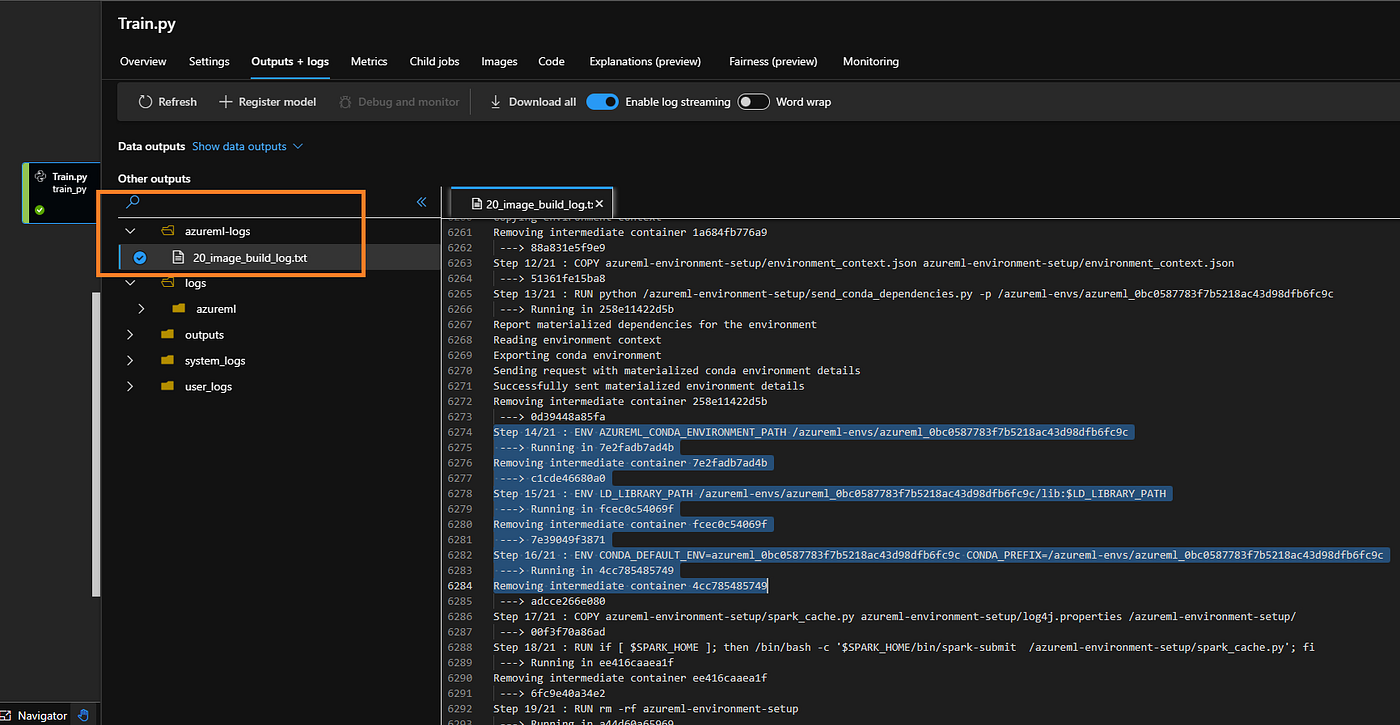
Container Image
CUDA Out Of Memory — CUDA HELL!
If you were to run your scripts without quantization (without the lines below), LLM load will result in CUDA OOM error if your GPU memory is not large enough. Re-emphasizes the value of BitsAndBytes library in optimizing QLoRA.
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
CUDA OOM Error
Telemetry
import os
os.environ["MLFLOW_EXPERIMENT_NAME"] = "AML-FINETUNE-ELEUTHERAI_GPT_NEOX_20B-LLM-V1"
os.environ["MLFLOW_FLATTEN_PARAMS"] = "1"Did we miss out on telemetry? We can enable it by leveraging MLFLow and adding the environment variables to the training script.
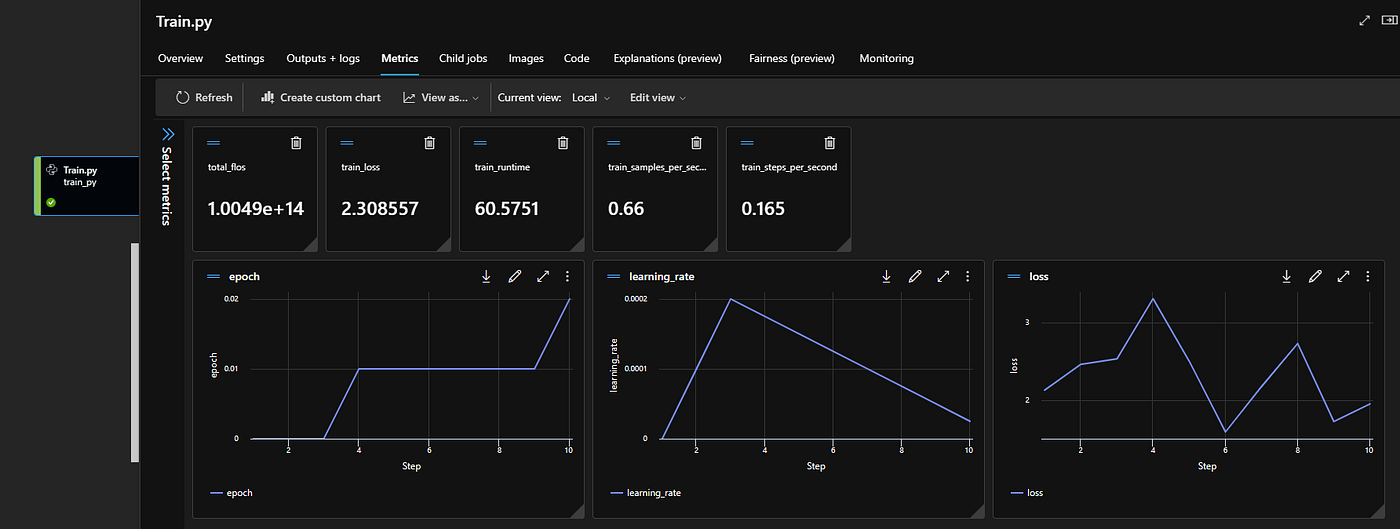
Model Training Metrics

Training Infrastructure Metrics
Interesting Fact: In the middle of training Falcon LLM. Looks promising!

Falcon LLM Model
Inferencing
Well! We have fine-tuned the model. Much goodness, yet to have an impact we must enable scalable operationalization. Let's look at enabling a rest endpoint for our fine-tuned model.
[Reference for Inferencing] https://github.com/keshavksingh/finetuning-llm-azureml/tree/main/llm-conda-inference
Below is the inferencing script.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("We are running on - "+ str(device) +"!")
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
device = "cuda:0"
lora_config = LoraConfig.from_pretrained("output")
model = get_peft_model(model, lora_config).to(device)
text_list = [
"Who is Satya Nadella?",
"What is the capital of France?",
"When was the last time India won the ICC cricket world cup?"
]
for text in text_list:
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Inferencing Output 1

Inferencing Output 2

Inferencing Output 3

Rest API
Here is a sample script for creating a quick Rest endpoint for the model.
https://github.com/keshavksingh/finetuning-llm-azureml/tree/main/llm-aci-inference
Final thoughts, it has been a tireless, determined, long-drawn effort to get to this point and be able to share this capability. However, I bring in a perspective, how “Microsoft and Azure are determined to enable every person and planet on earth to achieve more”. I am not just excited about the capability of generative AI and its diverse application but equally thrilled that Azure is not limiting OpenAI capabilities as SaaS offering but is also embracing OSS and enabling Azure’s robust and unparalleled compute capabilities for its consumers to generate value through an IaaS capability to fine-tune a tailored LLM. To AI and the future!
- This blog post was originally published at: https://blog.devgenius.io/
