This is part 6 of Developing Instagram Clone series, other parts are linked below
- Developing Instagram Clone: Introduction.
- Developing Instagram Clone: Discovery Service.
- Developing Instagram Clone: Auth Service
- Developing Instagram Clone: Media Service.
- Developing Instagram Clone: Post Service.
- Developing Instagram Clone: Graph Service.
- Developing Instagram Clone: Newsfeed Service.
- Developing Instagram Clone: Gateway Service.
- Developing Instagram Clone: Front-end Service
In this service we are trying to build a follow system. Any user can follow any other user, and the user will see the posts from users who he/she are following on his/her news feed.
Before we go deep into the graph service itself, let’s first discuss the best data-structure to represent this relationship and the database that we are going to use.
Graph data-structure
One might think why not saving a list of followers for each user in MongoDB or MySQL
This will work if you just want to query user followers, but if you want to get followers, following, mutual friends, or the shortest path between two users, you’ll have to write complex queries and it will have a great performance impact.
The best data-structure to represent this relationship is the graph data-structure.
Graph is a data structure where data is stored in a collection of interconnected vertices (nodes) and edges (paths).
The graph which we are going to build is called a social graph, where nodes are users and edges are the follow relation between users.
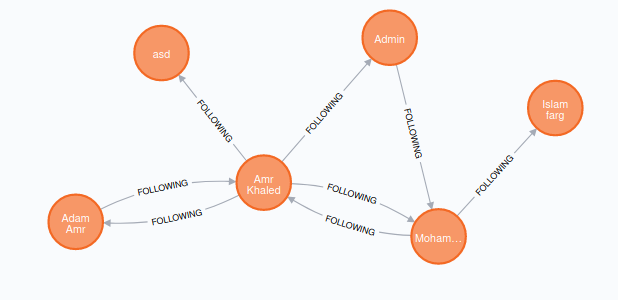
By applying depth first search (DFS), breadth first search (BFS) and Dijkstra algorithms, you can do the required queries efficiently.
Neo4j graph database
We will not implement a graph data-structure ourselves, we won’t implement it as efficient as Neo4j.
Neo4j is a database that models data in the form of graph. We will create a directional graph, which means if userA follows userB and vice versa, there will be two relations (edges) one from userA to userB and the other from userB to userA.
**Neo4j **has a query language called CQL stands for cypher query language.
We will use spring data neo4j which will create the schema, nodes and relationships for us without writing CQL but you can check CQL from here.
I will just highlight the “Match” query which corresponds to “Select” query in SQL.
MATCH (node1)-[r]->(node2) where n.field={} RETURN node2
This is the typical match query format, you specify the starting node, relation r and the end node. You can specify a filtering condition and the return value.
You can return starting nodes, ending nodes or the relation. You can also return the count, sum, or do some aggregations.
also notice the arrow, represent the relation direction, the above example the relation is from node1 -> node2 .
Let’s have a look at some example
MATCH (n)-[r]->() where n.username="amrkhaled" RETURN COUNT(r)
This one counts the number of out edges from the node which has a username “amrkhaled” (number of the users that amrkhaled is following).
MATCH (n:User{username:"amrkhaled"})<--(f:User) Return f
Here, notice the arrow direction is from f to n and then return f, which means return the followers of “amrkhaled”.
Neo4j on docker
It is the time now to uncomment Neo4j dependency in our docker compose file.
neo4j:
image: neo4j:latest
ports:
- "7474:7474"
- "7687:7687"
Neo4j browser
One last thing to mention before we go through the application code is that Neo4j provides a very fancy GUI which runs on port 7474
http://localhost:7474/browser/
#microservices #developer #web-development
