
I love building and writing about bag-of-words classification models, but HATE waiting for tokenizers to execute when I have a lot of text to analyze. A tokenizer is simply a function that breaks a string into a list of words (i.e. tokens) as shown below:

Since I have been working in the NLP space for a few years now, I have come across a few different functions for tokenization. In this blog post, I will benchmark (i.e. time) a few tokenizers including NLTK, spaCy, and Keras.
TL;DR: Don’t use NLTK’s wordtokenize use NLTK’s regexptokenize
Set-up
In this blog post, we will be timing a few different tokenizers. Obviously the timing is going to be dependent on the specific computer, but in general we are looking for the one that performs the best. Let’s start by importing a few packages.
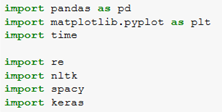
We will be using Python 3.6 and the versions of the other relevant packages are shown below:
Data Set
I am a healthcare data scientist, so in this blog post I will use the publically available MIMIC III dataset which is a set of deidentified medical data collected at Beth Israel Deaconess Medical Center in Boston, Massachusetts. If you would like to get access to this dataset, you can follow my instructions here. Let’s load the data into a pandas dataframe.

Here we will use the NOTEEVENTS.csv provided by MIMIC III which currently has over 2 million notes from a range of clinical note categories including discharge summaries, physician, consult, pharmacy, social worker, radiology, nursing, etc. The notes are contained in the column ‘TEXT’. We can find the length of each note in characters using:

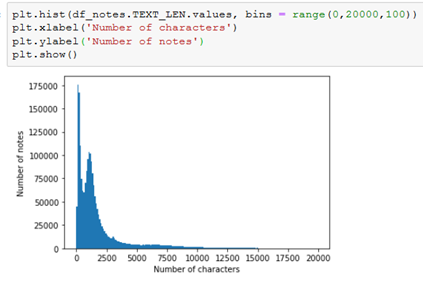
We can then plot a histogram to see we have a range of different lengths
For this post, we just need a list of notes, so let’s extract them from the pandas dataframe.

To make things simple later on, let’s shuffle the notes just in case there is an order to the MIMIC dataset.
Clean Text
In this post, we are going to write a few functions that follow this structure for each custom tokenizer
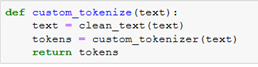
In most NLP tasks people tend to clean the data in some way, so we will use the same cleaning function with each custom tokenizer.
If we pass all punctuation and numbers to NLTK’s word_tokenize we end up with the following list
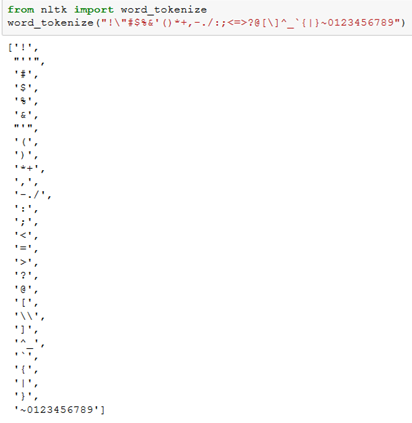
As we can see NLTK splits on some punctuation but not all and numbers are still included. Each custom tokenizer could have slightly different rules on splitting with punctuation.
For my particular NLP classification tasks, I have decided that all punctuation and numbers should be replaced with a space — to remove it and prevent combining of two words adjacent to the punctuation. I am also making the assumption that single quotes tend to be included in a contraction and I would like to make [can’t] turn into [cant] instead of two tokens[can, t], so we will replace single quotes with an empty character. To accomplish this I have created the following clean_text function

To demonstrate how to time a function, I will now time clean_text
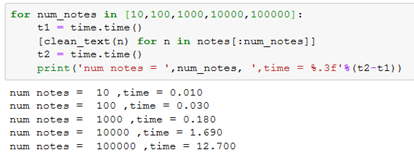
which demonstrates the time for a different number of notes ending with 100000 notes taking 12.7 seconds. Note that if you run this a few times you may get slightly different numbers depending on the state of your computer, but for the purposes of this post we will just run it once.
_____________________________________________________________________________
You might also enjoy: Python for NLP: Developing an Automatic Text Filler using N-Grams
_____________________________________________________________________________
NTLK’s word_tokenize
One of the standard tokenizers is wordtokenize which is contained in the NLTK package. We can make our function that uses cleantext and time it (saving the times) below:

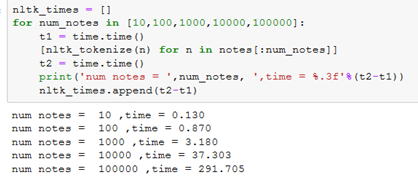
Well that’s just disappointing: it takes 5 minutes to just tokenize 100000 notes. This is kind of annoying if you are playing with hyperparameters of a Vectorizer for your NLP Bag-of-words model. Note that the cleaning function plays a minimal role with this tokenizer (12 seconds out of 291 seconds). Let’s see if we can do better.
Regular Expressions Tokenizer
Built into the standard python libraries is the re package which stands for regular expressions. The library contains functions for quickly searching through text. Here is our tokenize function that uses regular expressions:

It is amazing, look how fast regexp runs!
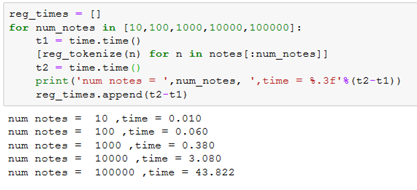
Clearly, NLTK wordtokenize must be adding extra bells and whistles to the tokenizer. I was curious what was included so I looked at the source code. All I was able to learn was that it uses a tree bank tokenizer. However, looking at the source code pointed me to another tokenizer in NLTK that just uses regular expressions: regexptokenize.

NLTK’s regexp_tokenize
The function and timing for regexp_tokenize is shown below
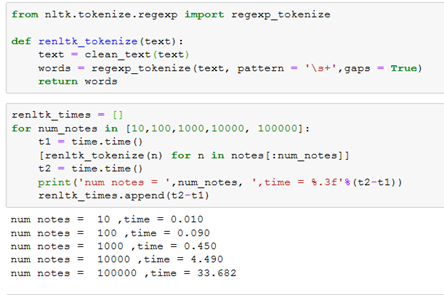
This is on par and perhaps even slightly better than just regular expression’s implementation!
spaCy tokenizer
Recently, I have been reading and watching a few tutorials about spaCy. The landing page for the package says “The library respects your time, and tries to avoid wasting it” which is encouraging to me. spaCy is very powerful and has a lot of built in functions to help with named entity recognition, part-of-speech tagging, word vectors and much more. However, for our simple task, all we need to do is tokenize.
I’m going to load the ‘en’ spaCy package and disable the named entity regonition, parser and tagger. This will remove some of the default options that we don’t ultimately need and would take time if we didn’t disable them.
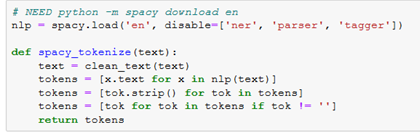
The timing is shown below:
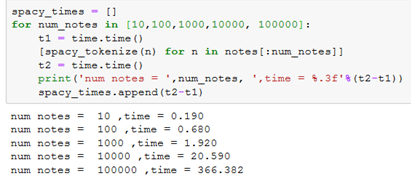
As you can see this isn’t as fast as the regexp tokenizers but is at least similar to NLTK’s word_tokenize . Obviously, there must be a few extra default options in spaCy’s tokenizer (more on this later).
Kera’s text_to_word_sequence
Keras is a very popular library for building neural networks in Python. It also contains a word tokenizer texttoword_sequence (although not as obvious name). The function and timings are shown below:
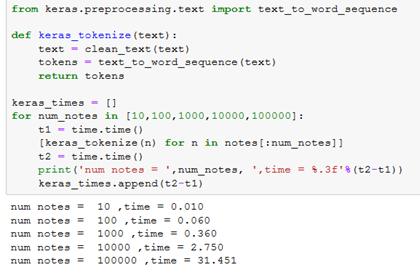
which is similar to the regexp tokenizers. If you look under the hood you can see it is also using regexp to split. Similarly, it also has options for filtering out characters which uses the same text.translate technique we used in clean_text.
We can plot the times for all these tests as shown below

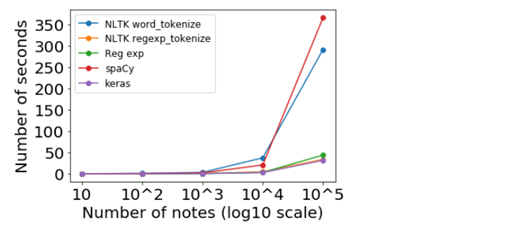
Benchmark of a few tokenizers
Vectorizer
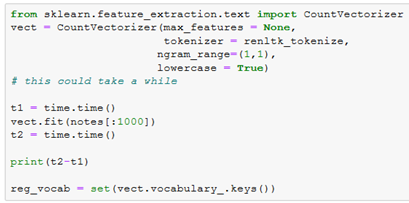
So far we have just been analyzing the times of executing the tokenizer function, which have suggested reg exp methods are the best. However, we have not investigated that the tokenizers produce the same results yet! For Bag-of-Words classifieres, we tend to use a tokenizer with some type of vectorizer (function for converting tokens into numerical columns). Here I will use the CountVectorizer from scikit learn’s package and extract the vocabulary. Note that I’m going to turn the max_features to None so I get all possible vocab because I noticed that one of the functions didn’t match!
Here is the code for getting the vocab for one tokenizer and is repeated for each tokenizer
.
spAcy was the only tokenizer that did not have the same vocab as the others. We can look at the vocab that is missing from spaCy’s set with the following:

This is interesting because they are all contractions, which probably means spaCy handles contractions differently. We can confirm this with the following:

Which sheds a bit more light on why spaCy takes longer than the regexp tokenizers.
Conclusion
In this post, we benchmarked a few different tokenizers. We learned that NLTK’s word_tokenize and spaCy have extra functionality built in by default adding significant time to execution. If you need the extra functionality, you’ll have to add time to the execution!
It appears regular expressions is currently the fast implementation and is also contained within NLTK and Keras. Let me know if you know of a faster solution!
Since I already have NLTK installed in most of my projects, I will be switching to regexptokenize instead of wordtokenize!
Originally published by Andrew Long at towardsdatascience.com

================================================
Thanks for reading :heart: If you liked this post, share it with all of your programming buddies! Follow me on Facebook | Twitter
#python
