Kubernetes vs. Docker
Kubernetes vs. Docker is a topic that has been raised numerous times in the industry of cloud computing. Whether you come from a non-technical background and need a quick introduction or if you need to make a business decision, I hope that the following few points will clarify this matter once and for all.
We need to look beyond the hype that surrounds both Kubernetes and Docker. What these words mean is important to grasp before running your business on top of them.
The Symbiosis Between Kubernetes and Docker
The question “Kubernetes vs. Docker?” in itself is rather absurd, like comparing apples to oranges. One isn’t an alternative to the other. Quite the contrary, Kubernetes can run without Docker and Docker can function without Kubernetes. But Kubernetes can (and does) benefit greatly from Docker and vice versa.
Docker is a standalone application which can be installed on any computer to run containerized applications. Containerization is an approach of running applications on an OS such that the application is isolated from the rest of the system. You create an illusion for your application that it is getting its very own OS instance, although there may be other containers running on the same system. Docker is what enables us to run, create and manage containers on a single operating system.
Kubernetes turns it up to eleven. If you have Docker installed on a bunch of hosts (different operating systems), you can leverage Kubernetes. These nodes or Docker hosts can be bare metal servers or virtual machines. Kubernetes can then allow you to automate container provisioning, networking, load-balancing, security and scaling across all these nodes from a single command-line or dashboard. A collection of nodes that are managed by a single Kubernetes instance is referred to as a Kubernetes cluster.
Now, why would you need to have multiple nodes in the first place? The two main motivations behind it are:
- To make the infrastructure more robust — Your application will be online, even if some of the nodes go offline, i.e, High Availability.
- To make your application more scalable — If workload increases simply spawn more containers and/or add more nodes to your Kubernetes cluster.
“Kubernetes automates the process of scaling, managing, updating and removing containers. In other words, it is a container orchestration platform. While Docker is at the heart of the containerization, it enables us to have containers in the first place.“
Differences Between Kubernetes and Docker
In principle, Kubernetes can work with any containerization technology. Two of the most popular options that Kubernetes can integrate with are rkt and Docker. However, Docker has won the greatest market segment and that has led to a lot of effort in perfecting the integration between Docker and Kubernetes, more than any other containerization technology.
Similarly, Docker Inc., the company behind Docker, offers their own container orchestration engine, named Docker Swarm. But even they realized the fact that Kubernetes has risen to the point that even Docker for Desktop (MacOS and Windows) comes with its own Kubernetes distribution.
If anyone was nervous about adopting Kubernetes for their Docker-based product, that last point would get rid of all of the doubts. Both projects have wholeheartedly embraced each other and have benefited tremendously from this symbiosis.
Similarities Between Kubernetes and Docker
These projects are more than technologies, they are a community of people, who, despite their differences, are is composed of some of the brightest minds in the industry. When like-minded individuals collaborate, they exchange bright ideas and learn best practices from one another.
These are some of such ideas that both, Kubernetes and Docker, share:
- Their love for microservice based architecture (more on this later).
- Their love for open source community. Both are largely open source projects.
- They are largely written in Go which allows them to be shipped as small lightweight binaries.
- They use human-readable YAML files to specify application stacks and their deployments.
In theory, you can learn about one without having a clue about the other. But keep in mind that in practice you will benefit a lot more if you start with the simple case of Docker running on a single machine, and then gradually understand how Kubernetes comes into play.
Let’s go deeper into this topic…
What Is Docker?
There are two ways of looking at Docker. The first approach involves seeing Docker containers as really lightweight Virtual Machines. The second approach is to see Docker as a software packaging and delivery platform. This latter approach proved a lot more helpful to human developers and resulted in widespread adoption of the technology.
Let’s look at the two different viewpoints more closely…
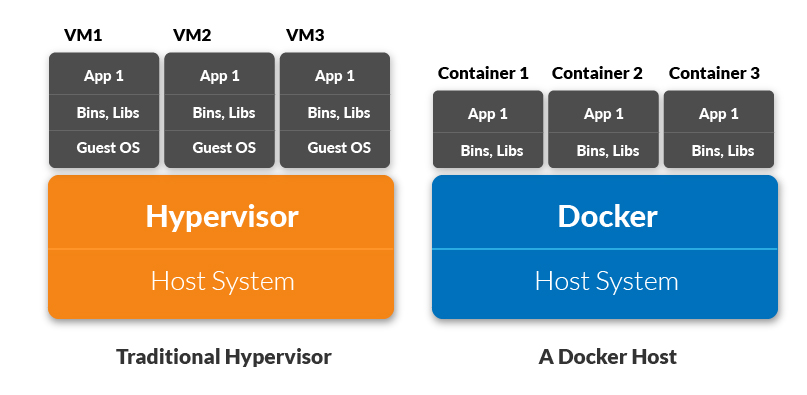
An Overview of Docker Containers
Traditionally, cloud service providers used Virtual Machines to isolate running applications from one another. A hypervisor, or host operating system, provides virtual CPU, memory and other resources to many guest operating systems. Each guest OS works as if it is running on actual physical hardware, and it is, ideally, unaware of other guests running on the same physical server.
VMware was one of the first to popularize this concept. However, there are several problems with this virtualization. First of all, the provisioning of resources takes time. Each virtual disk image is large and bulky and getting a VM ready for use can take up to a minute!
Second, and a more important issue, was the inefficient utilization of system resources. OS kernels are control freaks that want to manage everything that’s supposedly available to them. So when a guest OS thinks 2GB of memory is available to it, it takes control of that memory even if the applications running on that OS uses only half of it.
On the other hand, when we run containerized applications, we virtualize the operating system (your standard libraries, packages, etc) itself, not the hardware. Now, instead of providing virtual hardware to a VM, you provide a virtual OS to your application. You can run multiple applications and impose limitations on their resource utilization if you want, and each application will run oblivious to the hundreds of other containers it is running alongside.
Docker — As a Developer’s Tool
One of the problems that developers have is the difference between the production server, where the applications run, and their own dev machines (usual laptops and workstations) where applications are developed. Let’s imagine that you have Windows 10 running on your desktop but you want to write applications for Ubuntu 18.04. Maybe you are using Python v3.6 to write your application, while the Ubuntu server is still running at 3.4.
There are just too many variables to take into account and so we use Docker to abstract that complexity away. Docker can be installed on any OS, even Windows and Mac OS X are well-supported. So you can package your code into a Docker image, run and test it locally using Docker to guaranteed that the containers that were created from that Docker image will behave the same way in production.
Note: All the dependencies like the version of programming language, standard library, etc., are all contained within that image.
This way of looking at Docker images as a software package has led to the following popular quote:
“Docker will do to apt what apt did to tar.”
Apt, the package manager, still uses tar under the hood, but users never have to worry about it. Similarly, while using Docker we would never have to worry about the package manager, although it will still be present. Even when developing on top of say, Node.js technology, developers prefer building their Docker images on top of Node’s official Docker image.
So, that’s a brief overview of what Docker is and why one might want to know about it even if they are not involved in DevOps.
Let’s continue with Kubernetes now.
What Is Kubernetes?
Kubernetes takes containerization technology, as described above, and turns it up to eleven. It allows us to run containers across multiple compute nodes (these can be VMs or a bare metal server). Once Kubernetes take control over a cluster of nodes, containers can then spun up or torn down depending upon our need at any given time.
If you visit their official site, Kubernetes states its purpose quite plainly as:
“Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.”
So far we have represented only a brief overview of Kubernetes as automating a bunch of container creation. An app needs to have storage, and there are some Kubernetes DNS records to manage. You need to make sure that the participating compute nodes are securely connected with one another and so on. Having a set of different nodes instead of a single host brings a whole different set of problems.
A brief overview of the Kubernetes architecture will help us shed some light on how it manages to achieve all of this and much more.
Kubernetes Architecture — A Brief Overview
There is two basic concept you need to know about a Kubernetes cluster. The first is node. This is a common term for VMs and/or bare metal servers that Kubernetes manages. The second term is pod which is a basic unit of deployment in Kubernetes. A pod is a collection of related Docker containers that need to coexist together. For example, your web server may need to be deployed with a Redis caching server so you can encapsulate the two of them into a single pod. Kubernetes deploys both of them side by side. If it makes matter simpler for you, you can totally picture a pod consisting of a single container and that would be fine.
Coming back to the nodes, there are two types of nodes. One is the Master Node where the heart of Kubernetes is installed that controls the scheduling of pods across various worker nodes where your application actually runs. The master node’s job is to make sure that the desired state of the cluster is maintained.
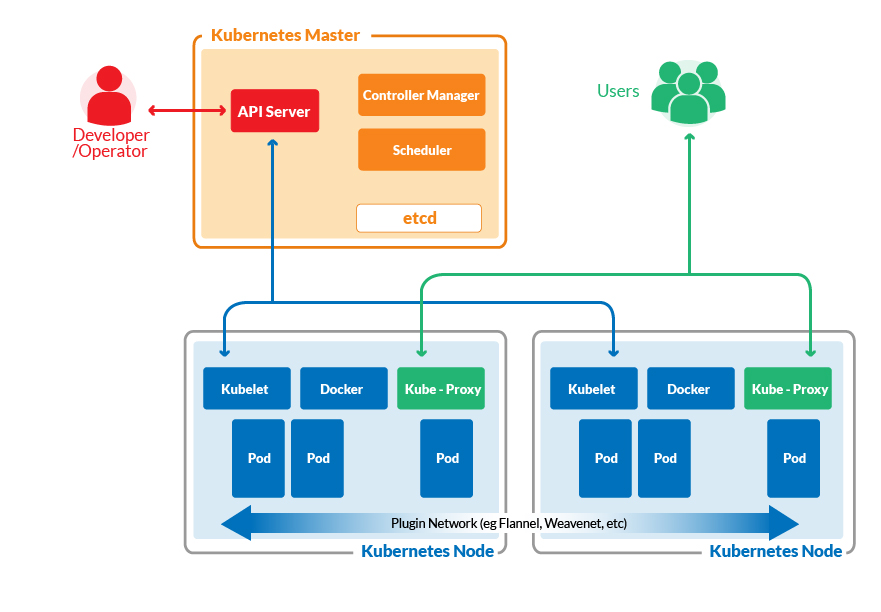
Here’s a brief summary of the Kubernetes’s diagram as shown above.
On Kubernetes Master we have:
- kube-controller-manager: This is responsible for taking into account the current state of the cluster (e.g, X number of running pods) and making decisions to achieve the desired state (e.g, having Y number of active pods instead). It listens on kube-apiserver for information about the state of the cluster
- kube-apiserver: This API server exposes the gears and levers of Kubernetes. It is used by WebUI dashboards and command-line utility like kubeclt. These utilities are in turn used by human operators to interact with the Kubernetes cluster.
- kube-scheduler: This is what decides how events and jobs would be scheduled across the cluster depending on the availability of resources, policy set by operators, etc. It, too, listens on kube-apiserver for information about the state of the cluster.
- etcd: This is the “storage stack” for the Kubernetes master nodes. It uses key-value pairs and is used to save policies, definitions, secrets, state of the system, etc
We can have multiple master nodes so that Kubernetes can survive even the failure of a master node.
On a worker node we have:
- kubelet: This relays the information about the health of the node back to the master as well as executing instructions given to it by the master node.
- kube-proxy: This network proxy allows various microservices of your application to communicate with each other, within the cluster, as well as expose your application to the rest of the world if you so desire. Each pod can talk to every other pod via this proxy, in principle.
- Docker: This is the last piece of the puzzle. Each node has a Docker engine to manage the containers.
There is, of course, a lot more of Kubernetes, and I encourage you to explore all of this.
Industry-Wide Adoption of Docker and Kubernetes
A lot of the concepts we have discussed so far sound good on paper, but are they economical? Will they actually help your business grow, reduce downtime and save resources both in terms of human hours and computing horsepower?
Docker in Production
The answer is simple when it comes to adopting Docker. Especially if you are adopting a microservice-based architecture for your software you should definitely use Docker containers for each microservice.
The technology is quite mature and very little can be said against it. Keep in mind, merely containerizing your code won’t make it better for you. Try avoiding monolithic designs and go for microservices if you actually want to make use of containerization platform.
Kubernetes in Production
One can’t be blamed for ranting about Kubernetes in Production and the reason behind it, in my personal opinion, is two-fold.
First, most organizations blindly jump without any understanding of the basic concepts of a distributed system. They try to set up their own Kubernetes cluster and use it to host simple websites or a small scalable application.
“This is quite risky if you don’t have an in-depth knowledge of the system. Things can easily break down”.
Secondly, Kubernetes is rapidly evolving, and other organizations are adding their own special sauce to it, like service mesh, networking plugins, etc. Most of these are open source and therefore are appealing to the operator. However, running them in production is not what I would recommend. Keeping up with them requires constant maintenance of your cluster and costs more human hours.
However, there are cloud-hosted Kubernetes platforms that organizations can use to run their applications. The worldwide availability of data centers that companies, like AWS, Azure, Joyent or GCE, offer can actually help you to get the most out of the distributed nature of Kubernetes. And, of course, you don’t have to worry about maintaining the cluster.
This is something small and medium scale organizations often miss. If you want to survive node failures and get high scalability you shouldn’t run Kubernetes on a single 1-U rack or even on a single data center.
So, Kubernetes in production? Yes, but for most folks, I would recommend cloud-hosted solutions.
Containers and A New Age of Cloud Computing
Docker wasn’t pitched as an OS-level virtualization software, it is marketed as a software packaging and delivery mechanism. The sole reason Docker containers got the attention that its competition didn’t is that of this software delivery approach.
Automated builds are a lot easier thanks to Dockerfiles. Complex multi-container deployments are now standardized thanks to docker-compose. Software engineers have taken containers to their logical extreme by providing complete CI/CD solutions involving building and testing Docker images and managing public or private Docker registries.
Kubernetes has freed containers from being stuck on a single computer, making the cloud an ever more enticing a place for this technology. Slowly, but surely, containerization will become the norm for every cloud dependent service and it’s, therefore, really important to adopt this technology earlier, rather than later. Doing so would minimize migration costs and associated risks.
A Case for The Distributed Operating System
Now that I have ranted about companies adopting Kubernetes without understanding it fully, allow me to make a case for why you should adopt Kubernetes. Cloud computing has evolved into this highly competitive market with Google, Microsoft, Amazon and many other players competing with one another.
This has drastically reduced the cost of deploying your software in the cloud. The best thing about Kubernetes is that it’s a largely open source, so you can understand what’s happening without getting too bogged down by the details.
Here is Azure pitching its Kubernetes service:
“Use Azure Kubernetes Service to create and manage Kubernetes clusters. Azure will handle cluster operations, including creating, scaling, and upgrading, freeing up developers to focus on their application. To get started, create a cluster with Azure Kubernetes Service.”
Just knowing how it works on surface-level lets you reason about your software as it is running in a distributed system. But you don’t have to worry about actually managing the underlying cluster!
Similar solutions are being offered by Amazon, Google and soon by DigitalOcean. Even small businesses and individual developers can now scale their applications across the entire planet. A little understanding of how it is achieved doesn’t hurt, so you should at least have a passing familiarity with Kubernetes and Dockers.
Every time you think, “Kubernetes vs. Docker?” naysayers would respond by saying Docker is cool, but Kubernetes is a little extreme. But the entire computer science is about extreme automation and Kubernetes takes the containerization model to its logical extreme!
More Subtle Differences — Networking
A lot of Kubernetes vs. Docker debates have roots in the basics like the implementation of storage stack and networking. Both of Docker and Kubernetes like to do things differently.
A container needs a lot more than just a CPU and some memory to be useful. There are a lot of subtle differences between running an application on a platform like Kubernetes vs. Docker hosts. These differences are too many to be mentioned concisely here, but one that always catches my attention is the networking side of things.
Kubernetes specifies that each pod should be able to freely communicate with every other pod in the Cluster, in a given namespace. Whereas Docker has a concept of creating virtual network topologies and you have to specify which networks you want your containers to connect to. Distinctions like these can really put off people trying to test the waters, but they are crucial when you consider the fundamental differences of Kubernetes vs. Docker:
“The former is meant to run across a cluster while the latter runs on a single node.”
There’s really no alternative to this dilemma and you just need to be patient as you move along the learning curve. Gradually, the bigger picture will become clearer to your eyes.
9. Adoption Mindset for Docker vs. For Kubernetes
With Docker, the benefits are rather obvious. If you ship your application on a Docker container, then it can also be run on any Linux distro. Even Illumos-based operating systems, which are not Linux at all, support Docker, and can run Docker containers.
Your application can actually be broken down into several microservices, in this way each microservice can be packaged as a Docker container. With a well-defined API, new features can easily be added to the existing one. For example, if you want analytics, just spin up a Hadoop container that can talk to the database.
Similarly, when it comes to Kubernetes, both users and cloud service providers can actually benefit largely by adopting it. Since it is based on containerization, cloud service providers can get a high density of containers efficiently using their resources, unlike traditional VMs. This allows them to significantly lower the price.
Users, on the other hand, can deploy their app across the globe reducing latency and improving the user experience.
The only exception to this shift would be desktop application developers. Since most desktop app may use the cloud for updates and/or backups, but they are designed mostly to run on a single machine.
Conclusion
Containers are amazing! They allow us to think about services and systems in a completely new and digital way. Both Docker and Kubernetes are here to stay. They are continuously changing to transform themselves into something better in the future. Keep your company involved in the Technology era and implement the containers that your infrastructure needs the most.
Designing newer software for a container-centric platform would not only make your apps more scalable but also more future-proof. Sticking to the old VMs might work for now, but a few years down the line you will eventually have to either bear the heavy cost of migrating everything into containers or abandon your projects altogether. Hopefully, now if someone brings up the topic of “Kubernetes vs Docker” you won’t get swept away by jargons.
#docker #kubernetes #devops
