Top 30 Python Libraries for Machine Learning
In this article, you’ll see top 30 Python libraries for Machine Learning.
Today, Python is one of the most popular programming languages and it has replaced many languages in the industry. There are various reasons for its popularity and one of them is that python has a large collection of libraries.
Python and Its Ecosystem
Python is one of the most widely used languages by Data Scientists and Machine Learning experts across the world. Though there is no shortage of alternatives in the form of languages like R, Julia and others, python has steadily and rightfully gained popularity.

Python has more interest over R and Julia consistently over the last 5 years
Similar to the Google Trends shown above(the plot is prepared using matplotlib and pytrends), confidence is visible year over year with python featuring way above its peers in the StackOverflow surveys for 2017 and 2018. These trends/surveys are the consequences of ease of use, shorter learning curve, widespread usage, strong community, large number of libraries covering depth and breadth of a number of research and application areas.
The amazing popularity might make one think that python is the gold standard for Machine Learning. This might be true to a certain degree yet, python isn’t free from criticism of being slow, issues with multi-threading, etc. It would be wrong to overlook its pitfalls and limitations.
Batteries Included
In this article, we will take you through an amazing ecosystem of libraries and projects which make python the go-to choice for Machine Learning. But before we start with the libraries, a small note about its “batteries included” philosophy. The batteries included philosophy refers to the all-powerful standard library which makes your life easier as a programmer.

The standard library (or if we take the liberty to say vanilla python installation), contains a set of easy to use modules for tasks ranging from handling JSONs, making RPC calls, emails, mathematical and statistical operations, regex, OS related operations and so on. All these and many more along with a powerful set of data structures like lists and dictionaries enable us to perform tasks with much more ease as compared to other languages. Checkout the page for standard library for more details: along with a good explanation here.
Core Data Handling Libraries:
1. Numpy

Python has a strong set of data types and data structures. Yet it wasn’t designed for Machine Learning per say. Enter numpy (pronounced as num-pee). Numpy is a data handling library, particularly one which allows us to handle large multi-dimensional arrays along with a huge collection of mathematical operations. The following is a quick snippet of numpy in action.

Numpy isn’t just a data handling library known for its capability to handle multidimensional data. It is also known for its speed of execution and vectorization capabilities. It provides MATLAB style functionality and hence requires some learning before you can get comfortable. It is also a core dependency for other majorly used libraries like pandas, matplotlib and so on. It’s documentation itself is a good starting point. Official Link.
Advantages
Numpy isn’t just a library, it is “the library” when it comes to handling multi-dimensional data. The following are some of the goto features that make it special:
- Matrix (and multi-dimensional array) manipulation capabilities like transpose, reshape,etc.
- Highly efficient data-structures which boost performance and handle garbage collection with a breeze.
- Capability to vectorize operation, again improves performance and parallelization capabilities.
Downsides
The major downsides of numpy are:
- Dependency of non-pythonic environmental entities, i.e. due to its dependency upon Cython and other C/C++ libraries setting up numpy can be a pain
- Its high performance comes at a cost. The data types are native to hardware and not python, thus incurring an overhead when numpy objects have to be transformed back to python equivalent ones and vice-versa.
2. Pandas
Think of relational data, think pandas. Yes, pandas is a python library that provides flexible and expressive data structures (like dataframes and series) for data manipulation. Built on top of numpy, pandas is as fast and yet easier to use.

Pandas provides capabilities to read and write data from different sources like CSVs, Excel, SQL Databases, HDFS and many more. It provides functionality to add, update and delete columns, combine or split dataframes/series, handle datetime objects, impute null/missing values, handle time series data, conversion to and from numpy objects and so on. If you are working on a real-world Machine Learning use case, chances are, you would need pandas sooner than later. Similar to numpy, pandas is also an important component of the SciPy or Scientific Python Stack (see for more details. Official Link.
Advantages
- Extremely easy to use and with a small learning curve to handle tabular data.
- Amazing set of utilities to load, transform and write data to multiple formats.
- Compatible with underlying numpy objects and go to choice for most Machine Learning libraries like scikit-learn, etc.
- Capability to prepare plots/visualizations out of the box (utilizes matplotlib to prepare different visualization under the hood).
Downsides
- The ease of use comes at the cost of higher memory utilization. Pandas creates far too many additional objects to provide quick access and ease of manipulation.
- Inability to utilize distributed infrastructure. Though pandas can work with formats like HDFS files, it cannot utilize distributed system architecture to improve performance.
3. Scipy

Pronounced as Sigh-Pie, this is one of the most important python libraries of all time. Scipy is a scientific computing library for python. It is also built on top of numpy and is a part of the Scipy Stack.
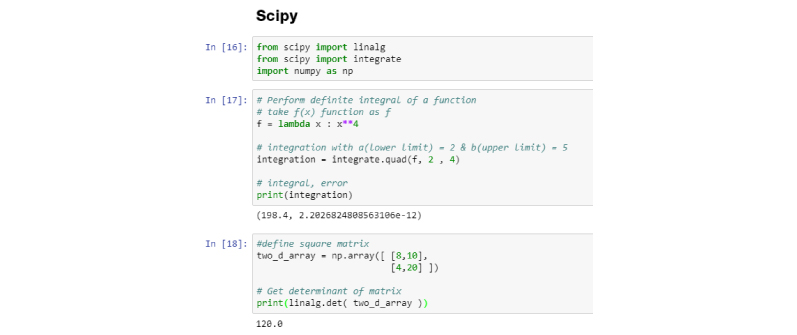
This is yet another behind the scenes library which does a whole lot of heavy lifting. It provides modules/algorithms for linear algebra, integration, image processing, optimizations, clustering, sparse matrix manipulation and many more. Official Link.
4. Matplotlib

Another component of the SciPy stack, matplotlib is essentially a visualization library. It works seamlessly with numpy objects (and its high-level derivatives like pandas). Matplotlib provides a MATLAB like plotting environment to prepare high-quality figures/charts for publications, notebooks, web applications and so on.

Matplolib is a high customizable low-level library that provides a whole lot of controls and knobs to prepare any type of visualization/figure. Given its low-level nature, it requires a bit of getting used to along with plenty of code to get stuff done. Its well documented and extensible design has allowed a whole list of high-level visualization libraries to be built on top. Some of which, we will discuss in the coming sections. Official Link:
Advantages
- Extremely expressive and precise syntax to generate highly customizable plots
- Can be easily used inline with Jupyter notebooks
Downsides
- Heavy reliance on numpy and other Scipy stack libraries
- Huge learning curve, it requires quite a bit of understanding and practice to use matplotlib.
Machine Learning Stars:
5. Scikit-Learn

Designed as an extension to the SciPy library, scikit-learn has become the de-facto standard for many of the machine learning tasks. Developed as part of Google Summer of Code project, it has now become a widely contributed open source project with over 1000 contributors.


Scikit-learn provides a simple yet powerful fit-transform and predict paradigm to learn from data, transform the data and finally predict. Using this interface, it provides capabilities to prepare classification, regression, clustering and ensemble models. It also provides a multitude of utilities for preprocessing, metrics, model evaluation techniques, etc. Official Link
Advantages
- The go-to package that has it all for classical Machine Learning algorithms
- Consistent and easy to understand interface of fit and transform
- Capability to prepare pipelines not only helps with rapid prototyping but also quick and reliable deployments
Downsides
- Inability to utilize categorical data for algorithms out of the box that support such data types (packages in R have such capabilities)
- Heavy reliance on the Scipy stack
6. Statsmodels

As the name suggests, this library adds statistical tools/algorithms in the form of classes and functions to the python world. Built on top of numpy and scipy, Statsmodels provides an extensive list of capabilities in the form of regression models, time series analysis, autoregression and so on.
Statsmodels also provides a detailed list of result statistics (even beyond what scikit-learn provides). It integrates nicely with pandas and matplotlib and thus is an important part of any Data Scientist’s toolbox. For people who are familiar and comfortable with R style of programming, Statsmodels also provides R-like formula interface using patsy. Official link.
Advantages
- Plugs in the gap for regression and time-series algorithms for the python ecosystem
- Analogous to certain R-packages, hence smaller learning curve
- Huge list of algorithms and utilities to handle regression and time series use-cases
Downsides
- Not as well documented with examples as sklearn
- Certain algorithms are buggy with little to no explanation of parameters
7. Boosting
Boosting is one of the ensemble methods to develop a strong classifier based on multiple weak-learners (bagging is its counterpart). Scikit-learn is one stop shop for most of your Machine Learning algorithm needs. It provides a good enough list of classification algorithms along with capabilities to build boosted models based on them. It also provides gradient-boosting algorithm out of the box.

8. Bagging Vs Boosting
Over the years, there have been a number of advancements in terms of improving the vanilla gradient boosting algorithm. The improvements have targeted both, its generalization and speed of execution. To bring these capabilities to python, the following are a few variants of the vanilla algorithm.
9. XGBoost
One of the most widely used libraries/algorithms used in various data science competitions and real-world use cases, XGBoost is probably one of the best-known variants.

A highly optimized and distributed implementation, XGBoost enables parallel execution and thus provides immense performance improvement over gradient boosted trees. It provides capabilities to execute over distributed frameworks like Hadoop easily. It also has wrappers for R, Java and Julia. Official Link.
10. LightGBM
Another distributed and fast variant of GBM (Gradient Boosting Machines), LightGBM is from the house of Microsoft. It is similar to XGBoost in most aspects, barring a few around handling of categorical variables and the sampling process to identify node split. LightGBM uses a novel method called GOSS (Gradient based One Sided Sampling) to identify node split. It also has the capability to utilize GPUs to improve performance. It is reported during some competitions that LightGBM is more memory efficient as compared to XGBoost. Official link
11. CatBoost

This Implementation from Yandex research is one of the leading variants of boosted trees. It provides capabilities similar to the two variants discussed above. It claims to be better at handling categorical variables and provides support for multi-GPU training. It is also one of the fastest algorithms when it comes to inference. Official Link
The three variants/competing implementations discussed above have a lot in common yet have some features better than the rest. To better understand the differences in the algorithms and their inference, check out the following article.
12. ELI5
Explain Like I am 5 (years old). Yes, this is what ELI5 stands for. It is great that we know how to develop models for different use cases but is there a way we can understand how does the model infer something? Some algorithms like decision trees are inherently explainable, yet not all of them are (at least not out of the box). ELI5 is one such library which provides the capabilities to debug classifiers and provide an explanation around the predictions.

Sample output from of TextExplainer.
It provides wrappers around different libraries like scikit-learn, xgboost, and many more to help understand the predictions. The library utilizes the algorithm described by Ribeiro et. Al called LIME (Local Interpretable Model-Agnostic Explanations) for many of the explainers. Official Link
**Deep Learning Frameworks : **
13. Tensorflow
Probably one of the most popular GitHub repositories and one of the most widely used libraries for both research and production environments. Tensorflow is a symbolic math library which allows differentiable programming, a core concept for many Machine Learning tasks.

Tensors are the core concept of this library which are generic mathematical objects to represent vectors, scalers, multi-dimensional arrays, etc.

It supports a range of ML tasks but it is primarily utilized for developing deep neural networks. It is utilized by Google (also developed by them) and a number of technology giants for developing and productionalizing neural networks. Tensorflow has capabilities to not just utilize multi-GPU stacks but also work with specialized TPUs or Tensor Processing Units. It has now evolved into this complete environment of its own with modules to handle core functionality, debugging, visualization, serving, etc. Official Link.
Advantages
- Industry grade package which has a huge community support with frequent bug fixes and improvements at regular intervals
- Capability to work with a diverse set of hardware like mobile platforms, web, CPUs and GPUs
- Scalability to handle huge workloads and works out of the box
- Well documented features with tons of tutorials and examples
Downsides
- Low-level interface makes it difficult to get started, huge learning curve
- Computation graphs are not easy to get used to (though this has been largely addressed with eager execution in version 2.0)
14. Theano

Let’s just start by saying that Theano is to deep learning what numpy is to machine learning. Theano (now a deprecated project) was one of the first libraries to provide capabilities to manipulate multi-dimensional arrays. It predates Tensorflow and hence isn’t as performant or expressive. Theano has capabilities to utilize GPUs transparently. It is tightly integrated with numpy, provides symbolic differentiation syntax along with various optimization to handle small and large numbers. Before the advent of newer libraries, Theano was the defacto building block for working with neural networks. Theano was developed and maintained actively by of Montreal Institute for Learning Algorithms (MILA), University of Montreal until 2017. Official Link
Advantages
- Ease of understanding due to its tight coupling with numpy
- Capability to utilize GPUs transparently
- Being one of the first deep learning libraries, it has a huge community to help and support issues
Downsides
- Once the workhorse for deep learning use-cases, is now a deprecated project which will not be further developed
- Its low-level APIs often presented a steep learning curve
15. PyTorch
PyTorch is a result of research and development at Facebook’s artificial intelligence group. The current day PyTorch is a merged project between pytorch and caffe2. PyTorch is a python first deep learning framework unlike some of the other well-known ones which are written in C/C++ and have bindings/wrappers for python. This python first strategy allows PyTorch to have numpy like syntax and capability to work seamlessly with similar libraries and their data structures.
It supports dynamic graphs and eager execution (it was the only one until Tensorflow 2.0). Similar to other frameworks in this space, PyTorch can also leverage GPUs and acceleration libraries like Intel-MKL. It also claims to have minimal overhead and hence is supposedly faster than the rest. Official Link
Advantages
- One of the fastest deep learning frameworks.
- Capability to handle dynamic graphs as opposed to static ones used by most counterparts
- Pythonic implementation helps in seamless integration with python objects and numpy like syntax
Downsides
- Still gaining ground and support, thus lags in terms of material(tutorials, examples, etc.) to learn from.
- Limited capabilities like visualizations and debugging as compared to a complete suite in the form of tensorboard for tensorflow.
16. Keras
Think simplicity, think Keras. Keras is a high-level Deep Learning framework which has eased the way we develop and work with deep neural networks. Developed primarily in python, it rests on the shoulders of giants like Theano, Tensorflow, and MXNet (also called as backends). Keras utilizes these backends to do the heavy lifting while transparently allowing us to think in terms of layers. For Keras, the basic building block is a layer. Since, most neural networks are different configurations of layers, working in such a manner eases the workflow immensely.

A typical Keras based Feed Forward Neural Network
Keras was developed independently by François Chollet for one of the research projects and has since been integrated as part of Tensorflow as well (though it continues to be developed actively and separately as well). Apart from providing an easy to use interface, it allows provides APIs to work with pre-trained state of the art models like RESNET, AlexNET, VGG and many more.
Advantages
- Easy to understand and intuitive interface helps in rapid prototyping
- Huge number of pre-trained models available for use out of the box
- Capability to work with different low-level libraries like tensorflow, theano, mxnet, etc.
Downsides
- Being a high-level library makes it difficult to develop custom components/loss functions (though it provides capabilities to extend)
- Performance is dependent on the underlying backend being used.
Others DL Frameworks/Libraries
Tensorflow, PyTorch, Theano and Keras are staple libraries when it comes to Deep Learning. These aren’t the only ones though. There are a number of other widely used libraries as well. Each born out of a specific need or due to issues with the popular ones. The following are a few more Deep Learning libraries in python:
17. FastAi
This a high-level library (similar to keras) built on top of PyTorch. As the name suggests, it enables the development of fast and accurate neural networks. It provides consistent APIs and built-in support for vision/image, text, etc.Official Link.
18. Caffe
Caffe or Convolutional Architecture for Fast Feature Embedding is a deep learning framework developed by Yangqing Jia for his PhD thesis. It was primarily used/designed for image classification and related tasks though it supports other architectures including LSTMs and Fully Connected ones as well. Official Link
**19. Apache MXNet **
One of the most widely used libraries when it comes to image related use cases (see CNNs). Though it requires a bit more boilerplate code but its performance makes up for it. Official Link
20. Gluon
Gluon is a high-level deep learning library/api from AWS and Microsoft. It is currently available through Apache MXNet and allows for ease of use of AWS and Microsoft Azure clouds. It is designed to be developer friendly, fast and consistent. Official Link.
NLP Libraries
21. NLTK
The Natural Language ToolKit or NLTK is a suite of offerings from the University of Pennsylvania for different NLP or Natural Language Processing tasks. The initial release was way back in 2001 and it has grown to provide a host of features. The list includes low-level tasks such as tokenization (it provides different tokenizers), n-gram analysers, collocation parsers, POS taggers, NER and many more.


NLTK is primarily for English based NLP tasks. It utilizes years of research into linguistics and machine learning to provide such features. It is widely used in academic and industrial institutions across the world. Official Link
Advantages
- The goto library for most NLP related tasks
- Provides a huge array of algorithms and utilities to handle NLP tasks, right from low-level parsing utilities to high-level algorithms like CRFs
- Extensible interface which allows us to train and even extend existing functions and algorithms
Downsides
- Mostly written in java, it has overheads and limitations in terms of the amount of memory required to handle huge datasets
- Inability to interface with the latest advancements in NLP using deep learning models
22. Gensim
Gensim is a fast and production ready NLP library. It is particularly designed for unsupervised topic modeling tasks apart from the usual set of NLP tasks. Out of the box, it provides algorithms such as Latent Semantic Analysis (LSA, LSI), matrix based (SVD, NMF) and Latent Dirichlet Allocation or LDA. It also provides functionalities for generating word representations using fastText and word2vec (and their variants).
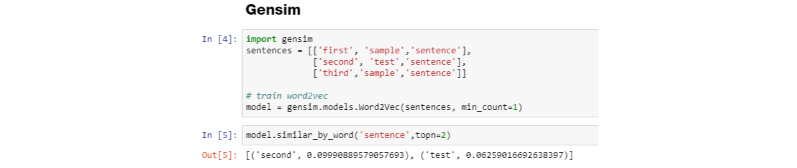
Word2Vec based similarity using Gensim
Gensim also has capabilities to handle large volumes of text using streaming and out of memory implementation of various algorithms. This capability along with robustness and efficient implementations set it apart from other NLP libraries. Official Link
23. Spacy
Spacy is a Natural Language Processing library designed for multiple languages like English, German, Portuguese, French, etc. It has tokenizers and NER (Named Entity Recognizers) for various languages. Unlike NLTK which is widely used for academic purposes, spacy is designed to be production ready.


Dependency Parser and its Visualization using Spacy.
Apart from providing traditional NLP capabilities, spacy also exposes deep learning based approaches. This enables it to be easily used with frameworks like Tensorflow, keras, Scikit-learn and so on. It also provides pre-trained word vectors in various languages. Explosion AI, the company behind spacy has also developed various extensions to enhance its capabilities by providing visualizations(displayCy), machine learning algorithms(Thinc), etc. Official Link
Visualization
24. Seaborn
Built on top of matplotlib, seaborn is a high-level visualization library. It provides sophisticated styles straight out of the box (which would take some good amount of effort if done using matplotlib).
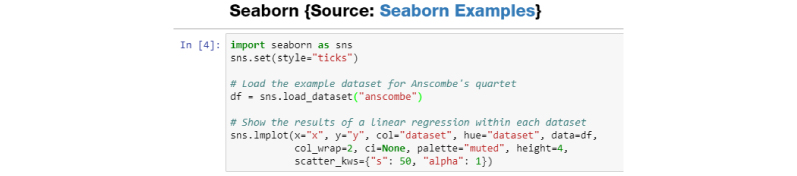
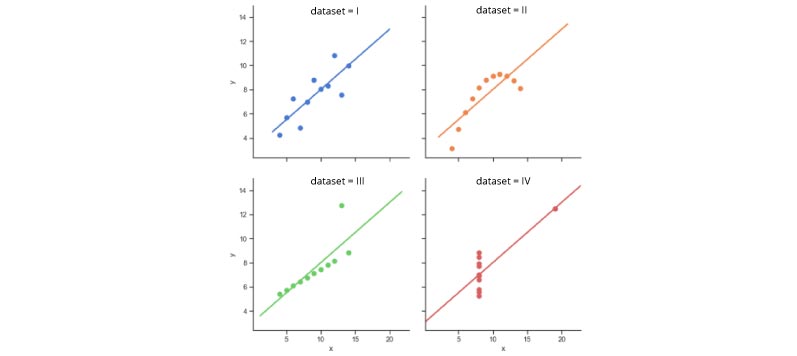
Sample plots using seaborn.
Apart from styling prowess and sophisticated color pallets, seaborn provides a range of visualizations and capabilities to work with multivariate analysis. It provides capabilities to perform regression analysis, handling of categorical variables and aggregate statistics. Official Link
25. Bokeh

Bokeh is short for visualization on steroids! No, this isn’t a joke. Bokeh provides interactive zoomable visualizations using the power of javascript in a python environment. Bokeh Visualizations are a perfect solution for sharing results through a Jupyter notebook along with its interactive visualizations.

It provides two modes of operation. A high-level mode for easily generating complex plots. It also has a low-level mode which provides much more controls for customizations. It is useful for preparing dashboards and other data related applications which are used through browsers. Official link
Advantages
- Capability to generate interactive visualizations with features like hover text, zoom, filter, select, etc
- Aesthetically superior visualizations
- low-level and high-level modes to support high flexibility and rapid prototyping
Disadvantages
- Inability to be packaged with saved state with jupyter notebooks
- The interface is slightly different than other visualization libraries, thus making it difficult to migrate from one library to another.
26. Plotly

Plotly is a production grade visualization platform with wrappers in not just python but other languages like R, Julia, MATLAB, etc. Plotly provides visualizations, online plotting, statistical tools along with a suite of solutions like Dash and Chart Studio to cater to different needs.

Plotly also provides capabilities to convert matplotlib and ggplot visualizations into interactive ones. It is extensively used by some of the industry leaders. Unlike most libraries discussed so far, plotly has commercial offerings as well. Official Link
Miscellaneous
So far we have discussed the most important, popular and widely used python libraries which are essential for different tasks within the Machine Learning workflow. There are a few more which are also used in the same workflows (or depending upon the use case/scenario). These might not be directly helping you build ML models/algorithms but these are nonetheless important in the overall lifecycle. Let us look at a few of them:
IPython and Jupyter
IPython or Interactive Python is a command line interface, originally developed for python (now supports multiple languages). It supports parallel computing and a host of GUI toolkits. It also forms the core of web application based notebook server called Jupyter. Jupyter is a loose acronym for Julia Python and R (thought now it supports more languages). It allows us to prepare and share documents which contain live code, interactive visualizations, markdown and slideshow capabilities.
IPython and Jupyter are the two most widely used shells/applications by Data Scientists to share their work and develop models.
Official Links:
27. Scrapy
Web or the internet is an immense source of data. Scrapy is one of the leading libraries utilized to scrape websites or build spiders/crawlers to do the same. It now also supports connecting to APIs to get data. Official Link
BeautifulSoup
Once you have the scraped text, the next requirement is the capability to extract information from HTML and XML data. Beautifulsoup is a library with capability to parse HTML and XML documents. It does so by generating parse trees from such documents. The documentation for Beautifulsoup is very nicely done and acts as a primer for most requirements. Official Link
29. Flask
Flask is a lightweight microframework for web in python. It is as bare bones a framework as possible to get up and running with a webserver/application. It supports extensions which enhance its capabilities to the full. Flask is based on Werkzeug (a Web Server Gateway Interface/WSGI) and Jinja 2 (a templating engine).

Hello World Example to get started with Flask.
Flask is used across the board, even some of the big industry players like LinkedIn. Official Link
30. OpenCV

Open Source Computer Vision or OpenCV for short is a computer vision library for python. It provides a huge list of computer vision related capabilities for handling 2D and 3D data. It is an actively developed project with cross-platform capabilities. It works well with deep learning frameworks like Tensorflow, PyTorch, etc. Official Link
Bonus: Few libraries/repositories which are quite widely used.
The python ecosystem is abuzz with new and exciting stuff every day. Researchers and developers are working to bring forward their work to improve your workflows and enhance the python ecosystem as well. The following is a quick list of more such work, some of which are yet available only as GitHub repositories:
- scikit-learn-contrib
- This is a collection of high quality scikit-learn compatible projects. Some of the projects from this collection include imbalanced-learn, lightning, hdbscan, etc. Officiallink
- Dask
- Dask is parallel computing python library. It works/integrates easily with existing libraries like pandas and numpy. It provides pandas like interface with the power of parallel computing. Official link
- keras_experiments
- This github repository further enhances the capabilities of keras. It exposes experimental work based on keras APIs. The primary goal is to provide capability to utilize multiple GPUs. Official Link
- data.table
- This library provides capability to work with and manipulate tabular data structures. The aim is to be analogous to R SFrames. The functionalities are similar to pandas (or restricted) and focus is towards big data. Official Link
Python Build System
pip and conda are two amazing package managers in the python ecosystem. For our understanding in this article, it suffices to know that these two package managers are what allow us to setup the required libraries.

The build system of python is a love-hate relationship. It is easy to use for most tasks, yet it can be mind-boggling to figure out setups for some of the most widely used libraries (say numpy, matplotlib). The tasks get slightly more complicated when you are working on an OS which has system-installed version of python. Proceed with caution and read installation steps before installing the libraries.
Conclusion

This article began by providing you the motivations and possible reasons behind python being the go-to choice for Machine Learning tasks. The python ecosystem is huge, both in terms of contribution and usage. We discussed about libraries used in all major areas of Machine Learning, right from data manipulation stage to deep learning, natural language processing and even visualization. Python has a diverse set of libraries available which not only enhance its capabilities but also showcase the breadth and depth of tasks one can perform. There are de-facto standards for most tasks (like scikit-learn, tensorflow, etc.) yet there is no dearth of alternatives. In the end we briefly discussed about the python build system and the issues associated with it. Through this article we have tried to provide you with an extensive list of libraries, yet this is by no means an exhaustive list. There are many more amazing libraries being used and worked upon. If you know any such, do share in the comments below.
#python #machine-learning
